
Finds patterns involving multiple events linked with specified correlation keys.
The correlate() function is given a pattern
to search for. The pattern describes multiple events and their
relations, for instance: an event of type A, an event of type B
and an event of type C, where the A and B events have the same
id1 value and the A event's
id2 value has the same value as the C event's
id3 value.
correlate() then searches for groups of
events matching that pattern. These groups of events in this
context are referred to as a
constellation.
The pattern may have temporal constraints - that is, there is a
further requirement that the events must come in a specific
order (see the
sequence
parameter).
Constellations may either involve events from anywhere in the
entire search timespan, or a constraint may be added that all
events of the pattern must be within a certain time interval
from each other (see the
within
parameter).
For a simple example, when searching for suspicious login
behavior, looking for a sequence of events involving failed and
successful logins may require looking for a sequence of failed
logins using the same login ID across multiple services. To
further investigate, correlate() can
identify a specific number of failure or successes, and/or
identify those events within a specific timeframe. Multiple
failed logins to multiple services with the same user ID within
a short period of time could indicate a compromise event.
| Parameter | Type | Required | Default Value | Description |
|---|---|---|---|---|
globalConstraints | array of strings | optional[a] | A list of fields which all events within a constellation must agree on. | |
includeConstraintValues | boolean | optional[a] | true | Whether to implicitly include the linked constraint fields from each query in the event output. |
| Values | ||||
false | Do not implicitly include fields from the constraints in the result set | |||
true | Include fields from the constraints in the result set | |||
includeMatchesOnceOnly | boolean | optional[a] | false | Matches events in the result set only once for each supplied query |
| Values | ||||
false | Allow a single event from a query to match within multiple constellations | |||
true | Only match an event once for each identified constellation | |||
iterationLimit | integer | optional[a] | 5 | Specifies a limit to the number of times correlate() will iterate over the events. This setting controls how much effort the function will spend to reduce the candidate event set into something manageable. If the candidate set still does not fit into memory after that point, a partial result will be reported. |
| Maximum | 10 | |||
| Controlling Variables | ||||
|
Variable default: | ||||
|
Variable default: | ||||
jitterTolerance | relative-time | optional[a] | A tolerance that makes matches less sensitive to the ordering of events when timestamps are very close in time, have different precision, or a known time skew (i.e. ingest delay). Increasing this value risks false positives in cases where order matters. Only relevant if The jitter tolerance must be less than or equal to | |
maxPerRoot | integer | optional[a] | 1 | Set the max number of matches to use from the root query (first query). |
query[b] | query | required | A list of the queries to be executed. Each query has the format QUERY_NAME: { QUERY } [ATTRIBUTE=VALUE], specifying the name, query definition and optional attributes. | |
root | string | optional[a] | first query | Name of the query to be used as the root node for the constellation. |
sequence | boolean | optional[a] | false | Whether events in a constellation must occur in the order they are declared. |
| Values | ||||
false | Events in a constellation can occur in any order | |||
true | Events in a constellation must occur in the order that queries are defined | |||
sequenceBy | array | optional[a] | When sequence=true, this specifies the event ordering to use. Contains a list of fields to compare by. Defaults to the timestamp. Requires sequence=true. | |
within | relative-time | optional[a] | Defines the maximum time span between earliest and latest matching events within a constellation. A smaller timeframe (like 15m) ensures tighter temporal correlation but may miss related events, while larger values allow for detecting longer-running activities. The value cannot be more than the time window of the parent query. | |
[a] Optional parameters use their default value unless explicitly set. | ||||
Hide omitted argument names for this function
Omitted Argument NamesThe argument name for
querycan be omitted; the following forms of this function are equivalent:logscale Syntaxcorrelate(Q1: {}, Q2: {})and:
logscale Syntaxcorrelate(query=Q1: {}, Q2: {})These examples show basic structure only.
To create a correlation query, specify the following elements:
Query criteria — Define two or more queries. Each query has a unique name that identifies the corresponding returned events.
Connections — Defines how events from different queries relate to each other to produce a correlation. These relationships determine which combinations of events constitute a valid match.
Correlation constraints (optional) — Define time-frame or sequence based constraints.
Sequence: enforcing the constellation (matched events) to occur in chronological order.
Within: enforcing the constellation to occur within a specific time frame.
sequenceandwithinare constraints on the correlation used to determine how the data should be compared.
The correlate() function is a type of query
that can iterate over data multiple times
and use the information extracted in previous iterations to
improve the result. This allows for events from multiple queries
to be matched against each other, and also connected to each
other by their time span or sequence.
Terminology for correlate()
correlate() is a special function which
introduces unique concepts which do not always have
counterparts elsewhere in LogScale. Here is a list of terms
for the different things involved in expressing a
correlate() query.
Query: a LogScale query defining events of a particular type. The queries are named, so that they can be referred to.
In the above example, there are three queries defining the kinds of events we're interested in.
Link: a connection between two queries, stating that we're interested in events which share a value in particular fields. A link goes from one field in one query to one field in another query. The two fields may have different names.
Occasionally, we're interested in more than two queries being connected through the same fields. (In the above example, this is the case for the ComputerName fields.) This can be expressed with more than one link, or in some cases with a global constraint.
Constraint: the criteria a set of events need to fulfill to be relevant, beside each event fulfilling their respective queries. The primary kind of constraint is the links, but there are others.
Constellation: A set of events which fulfill all of the criteria given, including the constraints. The result of the function is a list of constellations.
Global constraint: When all of the events need to agree on a particular field, this can be expressed as a global constraint on that field. This is a more concise way than writing the same constraint as a number of links.
Temporal constraints: constraints concerning the relative timestamps of the events of a constellation. See Sequence constraint and Within constraint.
Sequence constraint: A constraint which means that events of a constellation must come in a certain order (often by timestamp). See Correlation by Sequence.
Within constraint: A constraint which means that events of a constellation must occur 'close together' in time — with a given timespan. See Correlation by Timeframe.
Query Graph: A diagram of the queries and their relations. When you run a correlate() query, you can find a visualization of the query graph in the Query Graph tab. This can be used for instance to check whether the query is expressing the right event pattern and align your mental model.
correlate() Function Operation
The correlate() function has specific
implementation and operational considerations, outlined below.
The correlate() function is similar to
using join() and
defineTable() with
match(), in that it pulls together
different events through a common correlation key.
correlate() differs in how it operates,
though, and therefore provides different properties:
When using for
join()anddefineTable()the relations between the two queries to be joined is asymmetric, for example a left or right join may match more events on the right or the left side. See Query Joins and Lookups for more information.By comparison, within
correlate()it is symmetric, the events matched will be corresponding;correlate()is explicitly matching events according to the link criteria and constraints.While
join()anddefineTable()+match()can only join two queries,correlate()can join multiple queries.The limitation for
join()anddefineTable()is that the subquery result must fit in a query's result size quota. Forcorrelate(), the combined relevant events must fit within the quota. However, the correlation keys can be used to narrow down the set of relevant events for all of the queries.This means that
correlate()is particularly useful for use cases where:Three or more queries are to be correlated, but the correlation key relationships are such that they cannot be expressed with regular joins.
Two or more queries are to be joined, but each in isolation yields too large a result - as long as the correlation constraints narrow down the set of relevant events sufficiently. (Correlations are rare, but events which might be relevant are not.)
The correlate() function cannot be used
after aggregators or inside function parameters of other
functions (excepting subqueries which are run as their own
independent queries, such as in
defineTable()). It also cannot be used
after source functions such
ascreateEvents() or
readFile().
The output of the function is a list of rows, one per constellation that satisfies the specified constraints. See Output Format, which also describes how to select the fields included in the output.
correlate() Syntax
The syntax of the correlate() function is
like that of a normal function, except that it contains
queries which are named, and that each query may end with a
number of link constraints. In addition, certain attributes
may be specified per query. The structure is like this:
correlate(
NAME1: { QUERY1 [| LINK]* } [QUERYATTR],
NAME2: { QUERY2 [| LINK]* } [QUERYATTR],
NAME#: { QUERY# [| LINK]* } [QUERYATTR],
OPTIONS
)For example:
correlate(
LoginFail1 : { logon = FAILURE },
LoginFail2 : { logon = FAILURE },
LoginSuccess : { logon = SUCCESS } include: [user.email,platform],
globalConstraints=[user.id],
sequence=true,
within=15m
)
| groupBy([LoginSuccess.user.email, LoginSuccess.platform])In the above example:
There are three named queries,
LoginFail1,LoginFail2,LoginSuccess. LoginFail1 matches failed logins, LoginFail2 matches failed logins, LoginSuccess matches successful logins.Note
The underlying data may have come from multiple sources, so there are small differences in the field names used for common elements, for example the login email is in both user.email and user.id. The
correlate()function supports these differences by allowing for matching across different fields.For more information on the query format and options, see Defining a Query Node.
In the queries
LoginFail1andLoginFail2, the connection is defined asUserID, using the source event field user.id, the email used to attempt the login.In the query
LoginSuccess, the connection field is the source event field user.email which is the email of the successfully logged in user.The
globalConstraintsparameter defines how the values of each query are correlated with each other.The
sequenceandwithinare constraints on the correlation used to determine how the data should be compared.In this example, we are specifically looking for events in the given order, and within 15 minutes.
sequence=truerequires events to match in orderwithin=15mlimits matches to 15-minute windows
Note
When running the query and visualizing data in a
Table widget, for better
readability the UI automatically groups the fields by
prefix: for more information on this format setting, see
Group fields by prefix.
A more typical example might be:
correlate(
AuthError: {
#event_basetype="authentication_error" type="authentication_error"
} include: [username, error_code, service],
DatabaseError: {
#event_basetype="database_error" type="database_error"
} include: [query_type, table_name, error_message],
within=1h,
globalConstraints=[username]
)In this example, we are looking for a number of failure issues occurring within a short period of time across different applications:
The authentication error might happen first (user can't log in, then database queries fail)
OR the database error might happen first (database is down, then auth systems that depend on it fail)
Defining a Query Node
A query node must be defined in a specific way to be used as part of a correlation query.
A query node requires the following elements:
NAME— Identifies matching events in outputQUERY— Specifies the search criteriaLINK— Specifies link constraints between eventsQUERYATTR— Sets query-specific parameters
Each query within the list of queries submitted can be defined using the following syntax:
NAME: { QUERY [| LINK]* } QUERYATTRWhere:
NAMEThe identifying name for this query. The name is required, as it is needed to identify matching events in the output.
NAMEmust be an unquoted string.QUERYThe query to be executed. Contains the search criteria and returns events for correlation analysis and should define a filter for the events to be identified and matched.
Important
The query cannot not contain aggregate query functions.
LINKThe link variable declaration; that is, the constraint to use when matching across events. It uses the
<=>operator to establish connections.The link variable creates relationships between event fields, defining the fields to be used as common keys when joining queries. This can be specified either for each query, or by specifying a common field shared across all queries within the correlation.
The constraint works both as a search requirement and as the method of joining across all the events across all of the queries. For example:
logscaleLoginSuccess : { logon = "SUCCESS" | user.id<=>LoginFail1.user.id}The query will match for a specific user with a successful login, and match the field in the specified query. In this case, user.id in the
LoginFail1query. The effect here is for the correlation to look specifically for matching events for the user ID across preceding filter query, and then using the common field across all the queries in the correlation.Field correlation matches are defined using the
<=>operator. For example:logscaleComputerName<=>QueryName.FieldNameUses the field name ComputerName from the events returned by this query. To define a common field across all queries, use the
globalConstraintsparameter. When matching events, the corresponding fields will be used to join the events together across all the queries in the set.The source field names for each query do not need to be same; the role on the constraint in this case is to define the common value to be used to join the events.
Multiple fields can be defined to act as connection fields between queries. For example:
logscalecorrelate( LoginA : { logon = "FAILURE" | user.id<=>LoginB.user.id}, LoginB : { logon = "FAILURE" | user.id<=>LoginC.user.email | host.ip<=>LoginC.host.ip}, LoginC : { logon = "SUCCESS" | user.email<=>UserID | host.ip<=>LoginB.host.ip}, sequence=true, within=15m )In this case, matches are made for both connection fields. The connection fields do not need to be consistent across each query, so that different connections can be supported between different combinations of queries. In the preceeding, we are explicitly looking at the matching of both the user.id and host.ip in the last two queries, meaning that the first failure could occur on any host, but the success and the failure queries must match on both the host and user ID.
Important
The
<=>is the only operator supported for linking across events within thecorrelate(). For instance, the following will not work:Invalid Example for Demonstration - DO NOT USElogscale#event_simpleName=/DnsRequest/ | DomainName=/(?<sub_domain>.+).azurewebsites.net/ | DualRequest=1 | correlate( DomainOne: { sub_domain=* } include: [#cloud, cid, aid, ContextProcessId, DomainName, sub_domain], DomainTwo: { sub_domain=* | sub_domain != DomainOne.sub_domain } include: [#cloud, cid, aid, ContextProcessId, DomainName, sub_domain], within=1m, sequence=true, globalConstraints=[#cloud, cid, aid, ContextProcessId] )In this case, the query will be comparing sub_domain and the string
DomainOne.sub_domain.QUERYATTROne or more attributes specific to this query. For example, the list of fields to extract from each event matching this query can be defined here to provide additional information as part of the result set.
Supported attributes:
Enables selection of additional fields to be included in the events returned by this specific query. By default, the fields added in the event stream from this query will only include the fields defined in the connection constraints. To switch off inclusion of the constraint values in the dataset, set
includeConstraintValuestofalse.To specify additional fields, supply an array of fields. For example:
logscaleLoginC : { logon = "SUCCESS" | user.id<=>UserID} include:[firstname,lastname,computername]A wildcard can be used to include all fields:
logscaleLoginC : { logon = "SUCCESS" | user.id<=>UserID} include:*This will include all fields, but also adds additional memory overhead to include the data. On very large queries, this may have a significant impact on performance and memory usage. We recommend using
*only in the beginning where you author the query to look at the output result, then refine theincludewith the explicit fields you are interested in in the input before including it in your detection pipeline for instance running it as a trigger.
Output Format
Matching events are returned as a set of unified events where each field in the returned event is composed from the query name and the individual field. For example, given the query:
correlate(
LoginA : { logon = "FAILURE" | user.email <=> UserID},
LoginB : { logon = "FAILURE" | user.email <=> UserID | host.ip <=> HostIP},
LoginC : { logon = "SUCCESS" | user.email <=> UserID | host.ip <=> HostIP},
sequence=true,
within=15m
)Matching events would be returned with the following fields derived from the queries:
LoginA.user.email
LoginB.user.email
LoginC.user.email
LoginB.host.ip
LoginC.host.ip
Additional fields can be added using the
include
parameter.
When viewing within the UI, the Group fields by
prefix option can be used to view the events by
their correlated prefix. This is enabled by default when a
correlate() function is used.
For example:
 |
In the display, the output shows:
A row for each match
For each column in the original
correlate()query, a column for the corresponding fields returned.
Clicking on the ⋮ for a row will show the source events that make up the constellation, as seen in the video below:
All event results include the following additional fields as standard:
Correlation Options
The correlate() function includes a
number of additional parameters that can be used to adjust
the behavior of the correlation:
Correlating by Sequence
By default, correlation looks for matching constellations of events according to the constraint. To look for a sequence of events that match each query in the sequence to the
correlate()function, see Correlation by Sequence for more information.Correlating by Timeframe
By default, correlation looks for matching constellations of events according to the constraint. To look for a group of events within a given timespan that match each query in the
correlate()function, see Correlation by Timeframe for more information.
These options can be used separately, or together; correlating by a specific sequence within a specific timeframe.
Correlation by Sequence
Set sequence=true to
require events to match in chronological order.
When matching events across each query within
correlate() one or more constraints
can be added to the selection, which control how matches
across each event set are determined.
Using
sequence
set to
true
forces the constraint and correlation to require matching
events to occur in sequence (by their
@timestamp by default) as defined in
the list of queries. To change the field to be used for
the order, use the
sequenceBy
parameter.
For example, the query:
correlate(
LoginA: { logon = "FAILURE" },
LoginB: { logon = "FAILURE" | user.id <=> LoginA.UserID },
LoginC: { logon = "SUCCESS" | user.email <=> LoginA.UserID },
sequence=true
)Forces correlation only to occur if there were two login failures, followed by a success for this specific user. Other combinations (for example: SUCCESS, FAILURE, SUCCESS, or FAILURE, SUCCESS, SUCCESS) would not correlate.
To visualize, the following event sequence would match:
While this sequence would not correlate, because the sequence is incorrect:
The identification of this sequence covers the overall
query timespan. For example, if the query is searching
over the last 24 hours, the sequence will be matched if
that sequence occurs within that 24 hour timeframe. If the
event occurred multiple times, it will match multiple
times. To look for that specific sequence within a smaller
timeframe, use the
within
parameter.
By default, individual events can appear in multiple
correlation sets. To limit it so that each event can only
appear once in each event set, set the
includeMatchesOnceOnly
parameter to
true.
Correlation Field (sequenceBy Parameter)
By default, correlate() will sequence
by @timestamp and
@timestamp.nanos or
@ingesttimestamp based on the time
field chosen when the query was submitted.
If
sequenceBy
is set, the first field in the array will be compared
between two events, in the event they are equal,
correlate() will try to compare by
the next field and so on. The @id
field will automatically be used in the end as the final
tiebreaker.
For example, if the query has @ingesttimestamp, but you want to sequence by @timestamp and @timestamp.nanos:
sequenceBy=[@timestamp, @timestamp.nanos]If the income events have an order, to sequence lexicographically by order:
sequenceBy=[order]Controlling Matches with Jitter Tolerance
Because events can be registered with minor time differences, using correlated queries on event data with a specific sequence may not be identified correctly. Events occurring out of sequence due to small differences in the timestamps means that the events do not occur in the required sequence.
To account for this, correlate()
supports a
jitterTolerance
parameter which adds a tolerance to the sequence
correlation to allow for this difference. Use of this
option is only valid if
sequence is
set to
true. The
tolerance allows for matches within the given relative
time. For example, a
jitterTolerance
of
1m
would allow for the sequence to match even if individual
events were out of sequence within a minute of each other.
Note that this does not change the value of the
within
parameter, which defines the timespan of the overall
sequence, it only affects how individual events are
matched sequentially, for example allowing a single event
to occur up to a minute before, rather than after, an
event.
For example, with the following query:
correlate(
LoginA: { logon = "FAILURE" },
LoginB: { logon = "FAILURE" | user.id <=> LoginA.UserID },
LoginC: { logon = "SUCCESS" | user.email <=> LoginA.UserID },
sequence=true,
within=5m,
jitterTolerance=2m
)The corresponding event sequence is shown below, with events in red matching the correlation.
Event B and C (in red) will match the correlation (which is matching for Failure, Failure and Success, even though the sequence don't occur perfectly in sequence because the jitter tolerance means that the event overlap across the events still matches the required event sequence.
Correlation by Timeframe
Use the
within
parameter and Relative Time Syntax to
specify time windows for correlation matches.
For example, in the query:
correlate(
LoginA: { logon = "FAILURE" },
LoginB: { logon = "FAILURE" | user.id <=> LoginA.UserID },
LoginC: { logon = "SUCCESS" | user.email <=> LoginA.UserID },
within=5m
)
Each of the logon events across LoginA,
LoginB, and LoginC
must occur within 5 minutes of each to be considered a
match. During this time, the correlation may match
multiple times:
In the above sequence, the first two sets of events (Correlate A and B) match, because they both occur within 5 minutes of each other, but the third correlation (Correlate C) does not match because the span of the events is outside the timespan.
Identifying Multiple Matches using
maxPerRoot
When looking for matching events,
correlate() iterates over the events
for the given timespan multiple times and looks for
matching events across each defined query. By default, the
query will match the event correlation only once per root
query. The root query is by default the first query
defined in the correlation. The
root
parameter can be used to select an alternative root query.
When iterating over the events,
correlate() first looks for matches
for Query A, then looks for matching events in Query B,
and then determines whether the sequence or timeframe
matches apply. With
maxPerRoot
set to 1, the function will return the first match, to
return additional matches that originate from query A that
should be matched. For example, consider the event
sequence below:
There are six events, two with success (labelled A and C), and four with failures (B and D-F). With the query:
correlate(
LoginA : { logon = "SUCCESS" | user.email <=> LoginB.user.id },
LoginB : { logon = "FAILURE" | user.id <=> LoginA.user.email },
LoginC : { logon = "FAILURE" | user.id <=> LoginA.user.email },
globalConstraints=[user.id]
within=10m
)
With
maxPerRoot
set to 1, only the first correlation (X) will be returned
(matching events A, B and C). But within the given
timespan, there is a second correlation, events A, D and E
also match (Success, Failure, Failure). To return both
correlations,
maxPerRoot
must be set to 2:
The
maxPerRoot
allows you defined how many times the original query
criteria is used as the basis of each correlation.
Matching Events Only Once by using
includeMatchesOnceOnly
When correlating events, the
correlate() function will match
multiple sets of events if the correlation matches them,
and this could include the same event multiple times in
each correlation.
For example, consider the four events below:
When correlating for Success, Failure, Failure, the returned correlations could include:
E1, E2, E3
E1, E2, E4
E1, E3, E4
However, you may only want to consider event for a given
query to be part of a single correlated event. Setting
includeMatchesOnceOnly
to
true
would limit the responses to match only the first matching
combination, E1, E2, E3. This is because events E2 and E3
would now be excluded from future combinations.
Handling Multiple Matches for a Given Correlation
When using correlate() to match a
sequence of events multiple times across a collection of
events when performing a correlation across a time limit,
or particular sequence. You may want to control or limit
how events or permutations of events are included. When
attempting to zero in on a specific situation,
consideration should be given to whether you are aiming to
reduce by a root or anchor query as the core to the
correlation, or whether you are looking for unique
combinations. There are different solutions to this for
different situations.
For example, consider the following events:
From this list when performing a correlation looking for the sequence of Success, Failure, Failure within 10 minutes that it could match the following event sequences:
E1, E3, E4
E1, E3, E5
E1, E3, E6
E1, E4, E5
E1, E4, E6
E1, E5, E6
E2, E3, E4
E2, E3, E5
E2, E3, E6
E2, E4, E5
E2, E4, E6
E2, E5, E6
This represents all the different permutations available with that source of events. This can be handled in two ways:
Use
maxPerRootThis limits the number of times the root query in the correlation correlates with the other query matches. In this example:
maxPerRootResults 1 E1, E3, E4
E2, E3, E4
2 E1, E3, E4
E1, E3, E5
E2, E3, E4
E2, E3, E5
Using this method allows multiple matches across multiple events, but could still produce duplicate or false combinations in some situations because we are include the same events from other parts of the correlated query. Effectively limits the number of permutations from matching events in the root query,
Use
includeMatchesOnlyOnceThis limits each matching event to appear only once in a correlation. This reduces the number of duplicate events across the correlation, but depends on whether the events returned by correlated queries are uniquely identifiable or part of a wider pattern. If you are looking for pattern matches for a given sequence, it is likely you are looking for all the permutations.
Using correlate() with Saved Searches
The correlate() can be used with saved
searches to make correlation rules easier to write, especially
if combining queries, or using parameters, to simplify the
correlation queries.
A primary use case for this is to create a saved search to act as the basis for the common elements between different constraints. For example, creating a saved search with parameters to allow different forms of the query to be used:
correlate(
ConnectSSH:{$NetworkConnectIP4(aid=ExecuteSSH.aid,
ContextProcessId=ExecuteSSH.TargetProcessId)
...
}This simplifies the use of different queries or query elements into the correlation query.
Note
When editing a query that uses a saved query, the editor is
unaware of the contents of the saved query. That means, that
functions that have certain constraints - of which there are
many in correlate() - may have false
positives or negatives. As such it may appear to have errors
while actually working or appears to be fine when actually
resulting in an compile error when attempting to run the
query.
For example; a false negative (appears to have errors, but works when run):
correlate(
A: { * },
B: { $savedQuery() }
)Where $savedQuery() is:
foo <=> A.aFalse positive (appears to be correct, but fails when run due to duplicated link constraint):
correlate(
A: { * },
B: { $savedQuery() | foo <=> A.a }
)Where $savedQuery() is
foo <=> A.aWhen Should I Use correlate()
You can use correlate() when:
You want to pull together different events, through some correlation keys that conceptually link the events together.
The event patterns you're looking for can be expressed as a graph of events and these links (see below), plus optionally some timing constraints.
The result set is moderately small – that is, tens of thousands of results rather than millions.
In general,
correlate()is useful for finding the small number of events in a large volume of data. It is not designed to build or generate statistics over events. For that, use Query Joins and Lookups.correlate()can also be used efficient when processing large volumes of data where a typical join may fail due to the volume of information. Joins require a large volume of data to be kept in memory for processing.
How do I use correlate()?
The function is perhaps best explained using an example.
Let's first look at the use case and how it can be visualized as a graph, then how to solve it, and finally some terminology which will be used in the rest of this documentation.
An exampleSuppose you're looking for a particular pattern of suspicious activity in your logs: an Outlook process starts another process which then begins writing in a particular part of the file system.
That is, log-wise, we're looking for the combination of three things:
A
ProcessInfoevent which shows that a particular process is an outlook.exe process.A
ProcessSpawnedevent which shows that this process spawned some other process.A
FileOpenedForWriteevent which tells that this other process started writing a file somewhere in theC:\companydatafolder.
All happening on the same computer, of course.
Neither of these three kinds of events is particular rare or suspicious in themselves; it is the combination that is suspicious.
As a graphThe relations between the events we want to find can be expressed in the form of a diagram – a graph, with a node for each of the three events:
correlate() query
This use case can be solved using correlate() as follows:
correlate(
ParentInfo: {
#event=ProcessInfo
| FileName=outlook.exe
},
ChildSpawn: {
#event=ProcessSpawned
| ParentProcessID <=> ParentInfo.ProcessID
| ChildProcessID <=> ChildWriting.ProcessID
| ComputerName <=> ParentInfo.ComputerName
},
ChildWriting: {
#event=FileOpenedForWrite
| FilePath="C:\\companydata\\*"
| ComputerName <=> ParentInfo.ComputerName
}
)This is basically just the above diagram expressed as a LogScale query.
Let's look at its parts:
correlate(
ParentInfo: {
#event=ProcessInfo
| FileName=outlook.exe
},
ChildSpawn: {
#event=ProcessSpawned
| ParentProcessID <=> ParentInfo.ProcessID
| ChildProcessID <=> ChildWriting.ProcessID
| ComputerName <=> ParentInfo.ComputerName
},
ChildWriting: {
#event=FileOpenedForWrite
| FilePath="C:\\companydata\\*"
| ComputerName <=> ParentInfo.ComputerName
}
)The green parts are three queries expressing how to find each of the three kinds of events in isolation.
The yellow parts are names we give to those queries. They serve both to help make the query more readable, and as labels so that the queries can be referred to from elsewhere.
The blue parts
describe the relationships — the link — between
the different kinds of events. These links must be placed
after the end of the queries, and use a special operator
<=> called the link operator. On the left hand side is an
ordinary field name; on the right side is the name of a field
in a different query — this is where the query names
come into the picture.
correlate() Function Best Practice
Best practices for writing correlate queries:
| Best Practice | Explanation | Impact | |
| Performance | Limit field inclusion |
Use specific fields in include:[] instead of include:*
| Reduces memory overhead and improves query speed |
| Set appropriate time windows | Use the smallest practical within parameter | Narrows search scope and improves performance | |
| Configure iteration limits |
Set reasonable iterationLimit values
| Balances processing effort vs completeness | |
| Accuracy |
Use jitterTolerance
|
Add jitterTolerance when dealing with near-simultaneous events
| Prevents missing matches due to slight timing differences |
| Verify sequence requirements |
Only use sequence=true when order matters
| Ensures correct event pattern matching | |
|
Configure
Only relevant when sequence=true is set) |
Specify exact fields for ordering
( Multiple fields can be specified in priority order | Controls precise event sequencing | |
| Check field relationships |
Confirm all <=> operators connect valid fields
| Prevents incorrect correlations | |
| Structure | Start simple | Begin with basic correlations before adding complexity | Makes troubleshooting easier |
| Use meaningful query names | Give each query a clear, descriptive identifier | Improves readability and maintenance | |
| Document constraints |
Clearly specify globalConstraints and time windows
| Helps understand query behavior | |
| Debugging | Use Query Graph | Check the visual representation of relationships | Validates query structure |
| Test with small samples | Start with limited time windows for testing | Faster iteration and validation | |
| Verify field existence | Confirm all referenced fields exist in source data | Prevents null matches | |
| Maintenance | Comment complex queries | Document the purpose and expected behavior | Helps future maintenance |
| Use consistent naming | Follow a naming convention for queries and fields | Improves readability | |
| Regular validation | Periodically verify query results remain valid | Ensures continued accuracy |
correlate() Syntax Examples
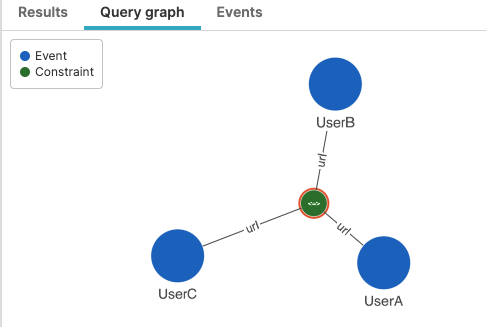
Example 1 — Look for URL's being accessed by specific users
In this example, the correlate() function
is used to look for constellations of events, where specific
users access the same URL. No order constraint is defined.
correlate(
UserA: { userid=peter },
UserB: { userid=geeta },
UserC: { userid=christian },
globalConstraints=[url]
)The Query graph tab in the UI represents the relationship between the correlated events (click the green node to display the fields as labels on the links):
|
Example 2 — Look for a user visiting a URL and getting different statuses
In this example, the correlate() function
is used to look for the constellation of events, where a user
gets an error response (for example
statuscode=4xx) when visiting a URL the first
time, followed by a successful response
(statuscode=200) the second time they visit the
URL. The parameter sequence=true is set to
require events to match in chronological order.
correlate(
ErrorResponse: { statuscode=/4\d\d/ },
SuccessResponse: { statuscode=200 | userid <=> ErrorResponse.userid | url <=> ErrorResponse.url },
sequence=true
)The UI's Query graph tab represents the relationship between the correlated events (click the green nodes to display the fields as labels on the links):
correlate() Examples
Click next to an example below to get the full details.
Correlate AWS Federation Token Generation with Console Logins
Correlate AWS CloudTrail events (GetFederationToken action and
ConsoleLogin action) by the same user within a 60-minute window
using the correlate() function
Query
#Vendor="aws" #event.kind="event" #event.module="cloudtrail"
| correlate(
GetFederationToken:{event.action="GetFederationToken"},
ConsoleLogin:{event.action="ConsoleLogin"
| user.name <=> GetFederationToken.user.name},
sequence=true,within=60m)Introduction
In this example, the correlate() function is used
to match AWS GetFederationToken events with corresponding ConsoleLogin
events for the same user within a 60-minute window, ensuring the events
occur in sequence.
The correlate() function finds relationships
between the events within the GetFederationToken and
ConsoleLogin queries.
sequence=true means that events in a
constellation must occur in the order that the queries are defined
within the time window
Example incoming data might look like this:
| @timestamp | #Vendor | #event.kind | #event.module | event.action | user.name | source.ip | aws.cloudtrail.event_id |
|---|---|---|---|---|---|---|---|
| 2023-06-15T08:00:00Z | aws | event | cloudtrail | GetFederationToken | alice.smith | 10.0.1.100 | a1b2c3d4 |
| 2023-06-15T08:01:30Z | aws | event | cloudtrail | ConsoleLogin | alice.smith | 10.0.1.100 | e5f6g7h8 |
| 2023-06-15T09:15:00Z | aws | event | cloudtrail | GetFederationToken | bob.jones | 10.0.2.200 | i9j0k1l2 |
| 2023-06-15T10:25:00Z | aws | event | cloudtrail | ConsoleLogin | bob.jones | 10.0.2.200 | m3n4o5p6 |
| 2023-06-15T10:30:00Z | aws | event | cloudtrail | GetFederationToken | charlie.brown | 10.0.3.150 | q7r8s9t0 |
| 2023-06-15T11:45:00Z | aws | event | cloudtrail | ConsoleLogin | charlie.brown | 10.0.3.150 | u1v2w3x4 |
| 2023-06-15T11:00:00Z | aws | event | cloudtrail | GetFederationToken | dave.wilson | 10.0.4.175 | y5z6a7b8 |
| 2023-06-15T12:15:00Z | aws | event | cloudtrail | ConsoleLogin | dave.wilson | 10.0.4.175 | c9d0e1f2 |
| 2023-06-15T12:45:00Z | aws | event | cloudtrail | GetFederationToken | eve.parker | 10.0.5.225 | g3h4i5j6 |
| 2023-06-15T12:46:15Z | aws | event | cloudtrail | ConsoleLogin | eve.parker | 10.0.5.225 | k7l8m9n0 |
Step-by-Step
Starting with the source repository events.
- logscale
#Vendor="aws" #event.kind="event" #event.module="cloudtrail"Filters for events from #Vendor=
awswith #event.kind=eventand #event.module=cloudtrail. - logscale
| correlate( GetFederationToken:{event.action="GetFederationToken"},Defines the first query named GetFederationToken to match AWS federation token generation events. Filters for events with event.action=
GetFederationTokenwhich captures all AWS Security Token Service (STS) federation token creation requests. - logscale
ConsoleLogin:{event.action="ConsoleLogin" | user.name<=>GetFederationToken.user.name},Defines the second query named ConsoleLogin to match AWS console login attempts. Filters for events with event.action=
ConsoleLoginwhich captures all AWS Management Console authentication events.The correlation relationship (condition) is specified using the
<=>The user.name field from this ConsoleLogin event must match the user.name field from the GetFederationToken event. The corresponding fields will be used to join the events together across all the queries in the set. This ensures that events will only be correlated when they relate to the same user's authentication sequence, preventing false correlations between different users' token generations and logins.
- logscale
sequence=true,within=60m)Sets correlation parameters:
sequence=trueensures that GetFederationToken events must occur before ConsoleLogin events.within=60mspecifies that the console login must occur within 60 minutes of token generation, matching the typical federation token validity period.
By default, the query will match the event correlation only once per root query (return the first match), as the
maxPerRootparameter is not specified.The
correlate()function outputs each pair of matched events as a single event containing fields from both sources, prefixed with their respective subquery names (for example, GetFederationToken.user.name, consoleLogin.@timestamp). Event Result set.
Summary and Results
The query is used to track the complete authentication flow for
federated users accessing the AWS Console, ensuring proper sequence and
timing of authentication events. The correlate()
function tracks authentication sequences by matching federation token
generation events with subsequent console login attempts within a
specified time window.
This query is useful, for example, to monitor federation token usage patterns, detect potential token sharing or misuse, and verify that console logins occur within expected timeframes after token generation.
Sample output from the incoming example data:
| @timestamp | GetFederationToken.user.name | GetFederationToken.source.ip | GetFederationToken.aws.cloudtrail.event_id | ConsoleLogin.@timestamp | ConsoleLogin.source.ip | ConsoleLogin.aws.cloudtrail.event_id | TimeBetweenEvents |
|---|---|---|---|---|---|---|---|
| 2023-06-15T08:00:00Z | alice.smith | 10.0.1.100 | a1b2c3d4 | 2023-06-15T08:01:30Z | 10.0.1.100 | e5f6g7h8 | 90 |
| 2023-06-15T09:15:00Z | bob.jones | 10.0.2.200 | i9j0k1l2 | 2023-06-15T10:25:00Z | 10.0.2.200 | m3n4o5p6 | 4200 |
| 2023-06-15T12:45:00Z | eve.parker | 10.0.5.225 | g3h4i5j6 | 2023-06-15T12:46:15Z | 10.0.5.225 | k7l8m9n0 | 75 |
Note that the following events are excluded from the results because
their ConsoleLogin occurred more
than 60 minutes after the
GetFederationToken:
charlie.brown's login at 11:45:00Z (75 minutes after token generation at 10:30:00Z)
dave.wilson's login at 12:15:00Z (75 minutes after token generation at 11:00:00Z)
This demonstrates how the
within=60m
parameter filters out login attempts that occur outside the expected
federation token usage window.
Note that the output includes timestamps from each query. The TimeBetweenEvents field shows the seconds between token generation and console login, useful for identifying unusual login patterns.
Correlate Authentication and Database Errors
Correlate authentication errors with subsequent database errors
within a 1-hour window using the correlate()
function
Query
correlate(
AuthError: {
#event_type="authentication_error"
} include: [username, error_code, service],
DatabaseError: {
#event_type="database_error"
| username <=> AuthError.username
} include: [query_type, table_name, error_message],
within=1h,globalConstraints=[username])Introduction
In this example, the correlate() function is used
to identify when authentication errors are followed by database errors
by matching events based on the username
(username field) within a 1-hour
window.
The correlate() function finds relationships
between the events within the AuthError and
DatabaseError queries. It helps identify patterns and
potential causality between events sharing common attributes.
Example incoming data might look like this:
| @timestamp | #event_type | username | error_code | service | query_type | table_name | error_message |
|---|---|---|---|---|---|---|---|
| 2023-06-15T10:00:00Z | authentication_error | john.doe | AUTH001 | login_service | <no value> | <no value> | <no value> |
| 2023-06-15T10:15:00Z | database_error | john.doe | <no value> | <no value> | SELECT | users | Table access denied |
| 2023-06-15T10:30:00Z | authentication_error | jane.smith | AUTH002 | admin_portal | <no value> | <no value> | <no value> |
| 2023-06-15T10:45:00Z | database_error | jane.smith | <no value> | <no value> | UPDATE | accounts | Insufficient privileges |
| 2023-06-15T11:00:00Z | authentication_error | bob.wilson | AUTH001 | login_service | <no value> | <no value> | <no value> |
| 2023-06-15T11:30:00Z | database_error | alice.jones | <no value> | <no value> | DELETE | logs | Operation not permitted |
Step-by-Step
Starting with the source repository events.
- logscale
correlate( AuthError: { #event_type="authentication_error" } include: [username, error_code, service],Defines the first query named AuthError to match authentication error events. Filters for events with #event_type=
authentication_error.include: [username, error_code, service]specifies which fields to include from matching authentication error events. - logscale
DatabaseError: { #event_type="database_error" | username<=>AuthError.username } include: [query_type, table_name, error_message],Defines the second query named DatabaseError to match database error events. Filters for events with #event_type=
database_error.The correlation relationship is specified using the
<=>include: [query_type, table_name, error_message]specifies which fields to include from matching database error events. - logscale
within=1h,globalConstraints=[username])Sets correlation parameters:
within=1hspecifies a 1-hour time window for matching events meaning that only events within 1 hour of each other will be correlated.globalConstraints=[username]ensures that correlated events share the same username value.
The
correlate()function outputs each pair of matched events as a single event containing fields from both sources, prefixed with their respective subquery names (for example, AuthError.username, DatabaseError.error_message). Event Result set.
Summary and Results
The query is used to identify and correlate authentication errors with subsequent database errors for the same user within a 1-hour window. It identifies potential security incidents where authentication errors are followed by database errors for the same user, which could indicate attempted unauthorized access.
The output demonstrates successful correlation of related security events, helping to identify potential security incidents where authentication issues are followed by database access problems.
This query is useful, for example, to detect potential security breaches, investigate access control issues, or audit user activity patterns.
Sample output from the incoming example data:
| @timestamp | AuthError.username | AuthError.error_code | AuthError.service | DatabaseError.@timestamp | DatabaseError.query_type | DatabaseError.table_name | DatabaseError.error_message |
|---|---|---|---|---|---|---|---|
| 2023-06-15T10:00:00Z | john.doe | AUTH001 | login_service | 2023-06-15T10:15:00Z | SELECT | users | Table access denied |
| 2023-06-15T10:30:00Z | jane.smith | AUTH002 | admin_portal | 2023-06-15T10:45:00Z | UPDATE | accounts | Insufficient privileges |
Note that the output includes timestamps from each query, allowing analysis of the time between authentication errors and subsequent database errors. Events without matching pairs within the time window are excluded.
Correlate Two Scheduled Task Events
Correlate two scheduled task events (registration and deletion)
within a 5-minute window using the
correlate() function
Query
correlate(
ScheduledTaskRegistered: {
#repo="base_sensor" #event_simpleName=ScheduledTaskRegistered RemoteIP=*
| upper(field=TaskName, as=scheduledTaskName)
} include: [*],
ScheduledTaskDeleted: {
#repo="base_sensor" #event_simpleName=ScheduledTaskDeleted RemoteIP=*
| upper(field=TaskName, as=scheduledTaskName)
| aid <=> ScheduledTaskRegistered.aid
| scheduledTaskName <=> ScheduledTaskRegistered.scheduledTaskName
} include: [*],
sequence=false, within=5m)Introduction
In this example, the correlate() function is used
to identify when scheduled tasks are registered and subsequently deleted
by matching events based on the task identifier
(aid field) and name
(TaskName field) within a
5-minute window.
The correlate() function finds relationships
between the events within the ScheduledTaskRegistered
and ScheduledTaskDeleted queries.
sequence=false means that events can
occur in any order within the time window
Example incoming data might look like this:
| @timestamp | #repo | #event_simpleName | aid | TaskName | RemoteIP |
|---|---|---|---|---|---|
| 2023-06-15T10:00:00Z | base_sensor | ScheduledTaskRegistered | aid123 | backup_task | 192.168.1.100 |
| 2023-06-15T10:02:00Z | base_sensor | ScheduledTaskDeleted | aid123 | backup_task | 192.168.1.100 |
| 2023-06-15T10:05:00Z | base_sensor | ScheduledTaskRegistered | aid456 | cleanup_task | 192.168.1.101 |
| 2023-06-15T10:07:00Z | base_sensor | ScheduledTaskDeleted | aid456 | cleanup_task | 192.168.1.101 |
Step-by-Step
Starting with the source repository events.
- logscale
correlate( ScheduledTaskRegistered: { #repo="base_sensor" #event_simpleName=ScheduledTaskRegistered RemoteIP=* | upper(field=TaskName, as=scheduledTaskName) } include: [*],Defines the first query named ScheduledTaskRegistered to match scheduled task registrations. Filters for events from #repo=
base_sensorwith #event_simpleName=ScheduledTaskRegisteredand any RemoteIP. RemoteIP=* ensures that the field exists.The
upper()function converts the TaskName field to uppercase and returns the converted results in a new field named scheduledTaskName.include: [*]ensures that the query includes all fields from matching events. - logscale
ScheduledTaskDeleted: { #repo="base_sensor" #event_simpleName=ScheduledTaskDeleted RemoteIP=* | upper(field=TaskName, as=scheduledTaskName) | aid<=>ScheduledTaskRegistered.aid | scheduledTaskName<=>ScheduledTaskRegistered.scheduledTaskName } include: [*],Defines the second query named ScheduledTaskDeleted to match scheduled task deletions. Filters for events from #repo=
base_sensorwith #event_simpleName=ScheduledTaskDeletedand any RemoteIP. RemoteIP=* ensures that the field exists.The correlation relationships (conditions) are specified using the
<=>The aid field from this ScheduledTaskDeleted event must match the aid field from the ScheduledTaskRegistered event, and similarly for the scheduledTaskName field. The corresponding fields will be used to join the events together across all the queries in the set. This ensures that events will only by dcorrelated when related to the same task instance.
include: [*]ensures that the query includes all fields from matching events. - logscale
sequence=false, within=5m)Sets correlation parameters:
sequence=falseallows events to match regardless of order.Setting the
sequenceparameter tofalsein this example is useful asdeletion eventscould theoretically be recorded beforeregistration eventsdue to system delays.within=5mspecifies a 5-minute time window for matching events meaning that only events within 5 minutes of each other will be correlated.
By default, the query will match the event correlation only once per root query (return the first match), as the
maxPerRootparameter is not specified.The
correlate()function outputs each pair of matched events as a single event containing fields from both sources, prefixed with their respective subquery names (for example, ScheduledTaskRegistered.aid, ScheduledTaskDeleted.@timestamp). Event Result set.
Summary and Results
The query is used to identify and correlate scheduled task registration and deletion events for the same task within a 5-minute window.
The output demonstrates successful correlation of scheduled task registration and deletion events, showing the complete lifecycle of tasks that were both created and deleted within the specified timeframe.
This query is useful, for example, to monitor task lifecycle patterns, detect unusual task deletion behavior, or audit scheduled task management activities.
Sample output from the incoming example data:
| @timestamp | ScheduledTaskRegistered.aid | ScheduledTaskRegistered.scheduledTaskName | ScheduledTaskRegistered.RemoteIP | ScheduledTaskDeleted.@timestamp | ScheduledTaskDeleted.RemoteIP |
|---|---|---|---|---|---|
| 2023-06-15T10:00:00Z | aid123 | BACKUP_TASK | 192.168.1.100 | 2023-06-15T10:02:00Z | 192.168.1.100 |
| 2023-06-15T10:05:00Z | aid456 | CLEANUP_TASK | 192.168.1.101 | 2023-06-15T10:07:00Z | 192.168.1.101 |
Note that the output includes timestamps from each query. In this case, this allows for analysis of the time between task creation and removal.