
Using Ad-hoc Tables
Ad-hoc tables in CrowdStrike Query Language provide a powerful mechanism for executing complex join operations and data analysis by generating temporary tables from query results that can be used in subsequent searches. The functionality supports various use cases including data enrichment, dynamic filtering, event correlation, cross-view data joins, and nested joins, while offering advantages over traditional join functions such as improved memory handling, higher row limits, and support for multi-cluster searches.
Ad-hoc tables provide a robust mechanism to handle complex join scenarios using CrowdStrike Query Language: they enable the execution of a query to generate tables whose results can be utilized in a subsequent search, allowing for dynamic and flexible data analysis.
The tables are generated using the defineTable()
query function. For more information, see
How to Use Ad-hoc Tables in Queries.
Conceptually, tables operate similarly to Lookup files, where the content is generated from one query's results and then matched with the primary query's results using either:
Inner Join expressed as a strict match with
match(... strict=true)or:Left Joins expressed as a non-strict match (for example, all values are included) with
match(... strict=false)
Find a detailed explanation of primary/subquery and inner/left join concepts at Query Joins and Lookups.
Ad-hoc tables serve the listed use cases well:
Data Enrichment. Ad-hoc tables facilitate the enrichment of your primary query results with data from one or more subquery queries.
Dynamic event filtering. Ad-hoc tables enable filtering events based on criteria defined in a subquery. For instance, you can look for actions performed by your most active users, where these users are identified by the results of the subquery.
Event correlation based on a common key. Similar to SQL inner joins, this use case involves correlating events based on a shared field. For example, you may want to retrieve information on the parent processes, limiting the data only to instances where the child process meets specific criteria.
Data join across multiple views or time ranges. Ad-hoc tables allow you to run queries on different views or time ranges than the primary query, enabling comprehensive data analysis across diverse datasets.
Nested joins. Results stored in an ad-hoc table can be used as an input to create a secondary table, providing an easy way to create complex, nested joins scenarios.
Ad-hoc tables are kept in memory as temporary tables that exist only within the scope of the current query. Ad-hoc tables do not create a persistent lookup file in the view or repository.
Important
Ad-hoc tables are not supported in Triggers at this point, for the reasons explained at Ad-hoc Tables in Live Queries. Use Scheduled searches instead.
Ad-hoc Tables vs. join()
In many scenarios, ad-hoc tables can be used in place of the
join() function. However, LogScale
generally recommends using ad-hoc tables due to the following
advantages:
Limits. Ad-hoc table subqueries adhere to standard LogScale query limits. While
join()subqueries' output is limited to 200k rows (in most environments), ad-hoc tables do not have a static rows limit. They rely on the query memory limit instead, which allows them to output more rows in many use cases.Improved query writing experience. As outlined in How to Use Ad-hoc Tables in Queries, ad-hoc tables make it easier to construct complex joins with a step-by-step approach, providing troubleshooting options along the way.
Right-join capability. Ad-hoc tables support right joins by combining the functions
defineTable(),readFile(),match(..., strict=false).Memory compression. When running live queries, ad-hoc tables are compressed in memory so they are more efficient in terms of resources, whereas
join()subqueries do not perform such compression.Support in Multi-Cluster Search. Ad-hoc tables are supported in multi-cluster views, whereas Join Query Functions are not. See Ad-hoc Tables in Multi-Cluster-Search for more information.
How to Use Ad-hoc Tables in Queries
Queries that leverage ad-hoc tables can be divided into two distinct parts:
Subquery (the table query) — generates results stored in an ad-hoc table.
Primary query — uses the results from the subquery as input for filtering or enrichment.
For an explanation of primary and subquery concepts, see Query Joins and Lookups.
Note
Because ad-hoc tables run as separate subqueries, they are not affected by query prefixes. For example, when used in dashboards, ad-hoc tables are not affected by dashboard filters, which are applied as prefixes to the main query only.
Ad-hoc tables are created via a straightforward step-by-step process, allowing for use of single or multiple nested tables, with results visible in the User Interface.
Write the subquery with
defineTable()at the beginning. This query executes first and saves the results in the ad-hoc table. In this example, results are saved in thetablenametable :logscale SyntaxdefineTable(query={*}, name="tablename", include=[name,username])Write the primary query to reference the ad-hoc table results. You can reference the table results using one of the following methods:
match()allows you to join the results of the ad-hoc table with your primary query, by referencing the ad-hoc table. To continue from the earlier example:logscale Syntax| match(table="tablename",field=fieldname, column=name)By default,
match()performs as the inner joinstrict=true. It also supports left joinsstrict=false.readFile(), used to perform a right-join on the table results. For example:logscale SyntaxdefineTable(name="table1", query={*}, include=[a,b]) | defineTable(name="table2", query={*}, include=[a, c]) | readFile(table1) | match(table2, field=a, strict=false)
If you are seeing unexpected results, you can check the results of your subquery in two ways.
Check ad-hoc table content in the UI.
When you use
defineTable()combined withmatch(), an additional panel appears next to Results for each subquery, displaying the results returned by the ad-hoc table. These tabs provide a preview of the first 500 rows of data, not limited to the rows that matched the primary query.
Figure 148. Ad-hoc table panel added in UI
The preview helps you validate the structure of the data, check column names, and confirm the existence of the rows with specific content.
Click to trigger a
readFile()query in a new panel, that allows you to search table contents using the CrowdStrike Query Language.In addition to the ad-hoc tables, any CSV file used within the query will also have its content displayed in a separate panel. This feature allows you to validate the results of any step of your query that uses the
match()function.Check ad-hoc table content by using the
readFile()function directly in your primary query (you will need to comment out the primary query for this). This can be combined with any necessary filtering query functions, to refine and inspect the data further. This step helps ensure that the data in the ad-hoc table is accurate and aligns with your expectations before it's used in the primary query.
Each table query and the primary query are executed in LogScale as separate queries — if your query includes one ad-hoc table, you will see two queries being submitted in the UI section.
Note
The subquery operates independently from the primary query. The primary query only runs after the subquery completes. The subquery cannot access fields from the outer query.
An overview of the ad-hoc table flow is shown in the following diagram.
Ad-hoc Tables in Multi-Cluster-Search
Ad-hoc tables allow you to perform join queries in Multi-Cluster Search views. Ad-hoc table queries are executed in Multi-Cluster Search as follows:
The subquery that defines the table runs on all remote clusters and send data back to the local cluster.
The local cluster builds a snapshot of the table, which aggregates data from all the clusters.
The snapshot of the ad-hoc table (the result of step #2) is distributed on all remote clusters, so it can be used in the primary query execution.
Ad-hoc Tables in Live Queries
Ad-hoc tables can be effectively used in live queries, with results updated in real time as new data becomes searchable. When a query is set to in the UI, both the subquery and the primary query run as live queries. However, because the primary query depends on the subquery's results, only the snapshots of the subquery results are captured in the ad-hoc table and used as an input to the primary query. LogScale optimizes the frequency of these snapshots to occur as often as possible, considering the time required for the system to execute the subquery, compress its results and distribute them across nodes.
The behavior is depicted in the following schema:
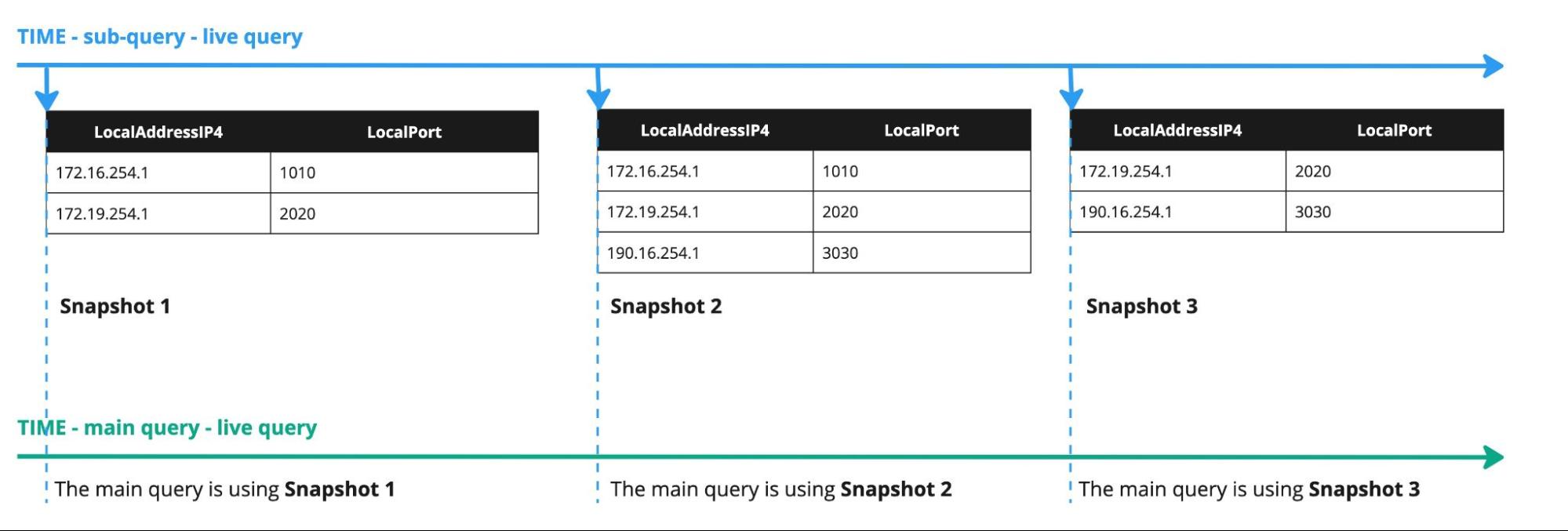 |
Figure 149. Ad-hoc tables in live queries
Due to the nature of the live query pipeline, this snapshot mechanism requires special consideration when implementing ad-hoc tables in your use cases. Specifically, when using a subquery for filtering (such as in an inner join), there is a risk that the ad-hoc table snapshot may lag behind the primary query, potentially causing it to miss relevant events.
To mitigate these challenges, we recommend using ad-hoc tables in live queries primarily in the following scenarios:
In enrichment use cases, when the enrichment data stays relatively consistent (it does not update in real time). Using live queries for this scenario allows your main query results to stay current, while still using the benefit of additional context coming from the subquery results.
In filtering use cases (inner joins) with relatively stable subquery results. For instance, when filtering for top values over an extended period, where the subquery result is unlikely to change rapidly within seconds. This stability of the results reduces the risk of the main query missing relevant events due to lag in the ad-hoc table snapshot.
Given the above considerations, ad-hoc tables are not supported in Triggers at this point.
Ad-hoc Tables Update Frequency and Cluster Performance
As described above, the update frequency of the ad-hoc table is
determined by the time it takes to execute the subquery, compress its
results and distribute them across nodes. Additionally, the value of the
dynamic configuration LiveAdhocTableUpdatePeriodMinimumMs
is added as a time buffer (set by default to
10s).
If a cluster is under a lot of pressure, very frequent table updates
might add to that. This could be observed as increased network traffic
and CPU usage for table generation. In this case
LiveAdhocTableUpdatePeriodMinimumMs could be increased to
reduce network traffic for tables and also generate less snapshots.
Ad-hoc tables vs. Lookup files
Both ad-hoc tables and Lookup Files provide methods to create dynamic lookup tables for matching query results. Both solutions share several similarities:
Usage in query executions. Ad-hoc tables and lookup files are utilized similarly during query execution. Their results are compressed in the same manner, and both are subject to the same maximum size limits and resource consumption.
Memory consumption. The contents of both ad-hoc tables and lookup files are loaded into memory in the same way. If the same content is used across multiple queries, it will only be loaded into memory once, optimizing resource usage and enhancing query performance.
Dynamic creation. Both ad-hoc tables and lookup files can be dynamically created based on the query results. Dynamic lookup files can be generated through Scheduled searches, while ad-hoc tables are created directly within the query.
Selecting between ad-hoc tables and lookup files depends on the specific use case and requirements. Here are some criteria to help guide your decision.
When to use lookup files:
Frequency of data updates. If you do not need frequent updates to the data, lookup files are the preferred choice. This is ideal when you are comfortable with the data being refreshed at a lower frequency and do not require results to be updated near real-time. For example, if your subquery is generating metadata over a long period of time (such as 30 days) and is not dependent on the time range of the main queries, Lookup files are a practical choice.
Reusability across multiple queries and users. When you need the data to be reused across multiple queries, dashboards, scheduled searches etc., using scheduled search to generate a lookup file can be easier to manage. While both solutions have an optimization mechanism that prevents the duplication of table content in memory, creating a scheduled search with a lookup file centralizes the management. This makes it easier to maintain and update the data in one place, rather than distributing the table definition across various queries
When to use ad-hoc tables:
Real-time subquery results. Ad-hoc tables are essential when you need the subquery results to refresh simultaneously with the main query. This is particularly important for filtering use cases.
Timeframe dependency on the main query. If the subquery's timeframe needs to be aligned with or relative to the main query's timeframe — such as being the same as the main query or offset by a specific interval — ad-hoc tables are a better choice. This ensures that the subquery dynamically adjusts based on the primary query's execution time, providing contextually relevant data.
Ad-hoc Tables Optimization
This section lists best practices to ensure optimal performance when working with ad-hoc tables.
When using ad-hoc tables, both the primary and the subquery queries are subject to the same limits as any LogScale queries. Therefore, use the general best practices for writing optimal queries.
To get more rows in the results, limit the columns in the
includeargument of thedefineTable()function to only those needed for the query. This reduces both the query state size and the result size, allowing to return more rows within the same resource constraint.Use a query with a smaller result set as your table subquery, then match it with the larger result of the primary query. Having a smaller result set in the ad-hoc table allows for more efficient query execution.
To use the same ad-hoc table across multiple queries, it is recommended to define them using the
defineTable()function within a saved query. You can then reference this saved query in multiple main queries. This approach combines the flexibility and advantages of the ad-hoc tables with the ease of centralized management, ensuring consistency and reducing maintenance effort across your queries.