
Normalize and Validate Against CPS Schema
LogScale can normalize and validate data against the CrowdStrike Parsing Standard (CPS) schema, to standardize field names and structures across different datasources for more consistent searching and analysis. This content covers key validation rules, error types, and practical steps for implementing CPS validation through the parser editor UI, including handling required fields, array validation, and proper field tagging.
Normalizing data simplifies writing queries that combine data across different data sources. Every incoming event generally has a notion of fields in its data, and extracting those fields into actual LogScale fields can range from easy to complicated.
The fields might be explicitly named (as JSON for example), or unnamed but still structured (CSV data for example), in which case extracting them is fairly easy. Or the fields might not look like fields at all, and have little structure or naming in the first place. The latter can happen for events which are written for human consumption.
For example, consider a log message like:
"User Jane logged in", here a parser
author has to decide whether the user name should be a field or not,
and if it should, then the parser has to be very precise about how it
extracts that name.
This means that parsing different types of incoming events can mean those events look very different from each other when stored in LogScale. That is, even if three different log sources contain similar information, like a source IP address, they might represent it differently. Each type might name the field containing the address differently (sourceIp, sip, source_ip, etc.), and one type may append the port number to the IP for example. All of this makes it hard to search across different types of logs, because you have to know the names and peculiarities of each type to search correctly.
Solving this problem requires data normalization, and LogScale has different levels where this can be applied at. We recommend two approaches if you wish to apply normalization: doing so in the parser, or using Field Aliasing to rename fields after ingestion.
An important aspect of normalization is to choose what to normalize to. In this case, we recommend CrowdStrike Parsing Standard (CPS) 1.1 as the standard to adhere to. This is also the standard which our parsers in the LogScale Package Marketplace use, so you can look at them for good examples.
To make it easier to write parsers which need to modify a lot of fields, the editor for the parser script has auto-completions for field names. The suggested field names are taken from the test cases of the parser, so any fields outputted for a test case are available for auto-completion:
 |
Figure 70. Auto-completion in Parser Script
Table: CPS Validation Schema Errors
| Error Message | Explanation | Solution |
| The field has a near duplicate. Please only keep one of the following fields: [${variations}] | Indicates that some fields are too similar to each other, and there should only be one "version" of the field. E.g. you should not have @event.kind and event.kind on the same event. |
Use drop() to remove one of the fields.
Alternatively, you can use rename() if
you wish to preserve the value under another field.
|
| Required field is missing | Indicates that the field is required. This is an exact match, i.e. if @event.kind is required it will only match @event.kind it will not match event.kind |
Assign a value to the field.
It may also be the case that your value extraction is
incorrect, or that you have a similar field that should be
renamed ( |
| Convert ${subfield} to an array. |
Indicates that a fieldset entry point has defined the element to be an array but it isn't. The ${subfield} string specifies which part of the field should be turned into an array. |
Use array:append() to turn this field
into an array
|
| The schema expects ${subfield} to not be an array. | This field cannot be an array. See Array Syntax for array syntax details. |
You have a field with the structure
array[idx]. If you
only have a single value, you can use
rename() to turn it into a field without
an index. If you have multiple values in this array, you may
want to rename the array or reconsider storing these values as
an array.
|
| The value ${actualValue} is not one of the accepted values: [${acceptedValues}] | Indicates that the value of the field does not match one of the accepted values for that field. | Update your parser script to assign one the accepted values to the field. |
| The field should be tagged | A tag that can be created from this field is expected. |
You should consider tagging this field, see Parsing Event Tags. If you do not believe this field should be tagged, use the rename() function to rename the field such that it can no longer result in the expected tag or use drop() to remove the field from the event. |
Using CPS Validation
When you run your parser against your test data with CPS validation, we verify if your parser follows the following rules:
Fields must be tagged if there is a field that could be mapped to that tag with #. For example: @observer.type or observer.type are variations of the required tag #observer.type. Therefore, they should be resolved as a tag. CPS validation will flag this as an error. .
Fields that should be arrays according to CPS are indeed arrays.
Fields that should not be arrays according to CPS are not arrays.
Validate that a given field contains a valid enum value
The parser sets all the Required Fields.
To verify that a parser normalizes test data to the CPS schema, use the parser validation tooling from the parser editor UI:
Add test data as described in Custom Parsers.
Click the Use CPS checkbox to validate against the CPS schema.
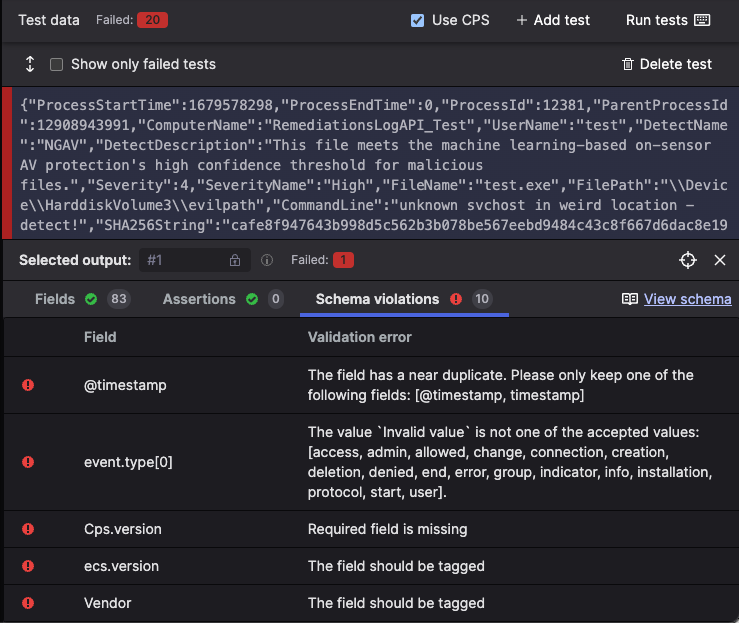 |
Figure 71. CPS Validation