
Split an event structure that includes an array into multiple distinct events with each array element.
Hide omitted argument names for this function
Omitted Argument NamesThe argument name for
fieldcan be omitted; the following forms of this function are equivalent:logscale Syntaxsplit("value")and:
logscale Syntaxsplit(field="value")These examples show basic structure only.
split() Function Operation
When LogScale ingests data into arrays, each array
entry is turned into separate attributes named
[0],
[1],
... This function takes such
an event and splits it into multiple events based on the
prefix of such [N] attributes, allowing for aggregate
functions across array values.
When the function is called, each split event generated is given a unique index ID in the _index field. This can be used to identify the individual event.
If the event data includes an @id field,
then the @id field is split into multiple
fields to identify each array element, with the string
__ and the index number appended. For
example, given the input record:
| "@id=1", "a=[1,2,3]" |
When executing:
split(a)Generates the following events:
| @id | _index | a |
|---|---|---|
| 1__0 | 0 | 1 |
| 1__1 | 1 | 2 |
| 1__2 | 2 | 3 |
Memory Usage of split() on Large Fields
The split() function is not very
efficient, so it should only be used after some aggressive
filtering.
When the split() function creates new
events from an array, it copies ALL fields, except the array
that is split, from the original event into each new split
event by default. This includes large fields like
@rawstring.
When splitting an event containing large fields like @rawstring, the function creates multiple copies of that data. For example, a 1MB @rawstring split into 100 events would consume 100MB of memory.
The impact is affected by how the query operates and what
other operations are occurring in the process. If the
split() is followed by an operation
that summarizes or aggregates the data, for example:
split(array) | count()The memory impact is small, as the original field is not copied to further events.
If, however, the split is combined with other data; the data
is not filtered; or it is used to return a larger data set
using tail(max) then the
impact will be higher as the copied data will increase the
overall query size.
The impact also depends on whether the operation is being used as a part of a parser or during a query operation:
During Parsing
When using
split()during parsing data during ingest, the effect ofsplit()increases memory usage and can also increase the amount of data stored on disk as the event data is copied to each new event.In this case, best practice is to drop any unnecessary large fields before using
split(). For example:logscale| drop(@rawstring) | split(array_to_split)During Querying
Care should be taken to ensure that data is not copied to multiple events during the query process, but it depends on whether the original field is retained and copied to new events in the process. This can be mitigated with the same technique above, dropping the original field or @rawstring before continuing the query.
split() Syntax Examples
In GitHub events, a PushEvent contains an array of commits,
and each commit gets expanded into subattributes of
payload.commit_0,
payload.commit_1,
.... LogScale
cannot sum/count, etc. across such attributes.
split() expands each
PushEvent into one
PushEvent for each commit so
they can be counted.
type=PushEvent
| split(payload.commits)
| groupBy(payload.commits.author.email)
| sort()There might be a case where your parser is receiving JSON events in a JSON array, as in:
[
{"exampleField": "value"},
{"exampleField": "value2"}
]In this case, your @rawstring text contains this full array, but each record in the array is actually an event in itself, and you would like to split them out.
First you need to call parseJson(), but
when @rawstring contains an array, the
parseJson() function doesn't assign names
to the fields automatically, it only assigns indexes. In other
words, calling parseJson() adds fields
named something like
[0].exampleField,
[1].exampleField, etc. to the
current event.
 |
Since split() needs a field name to
operate on before it reads indexes, it seems like we can't
pass it anything here. But we can tell
split() to look for the empty field name
by calling split(field="").
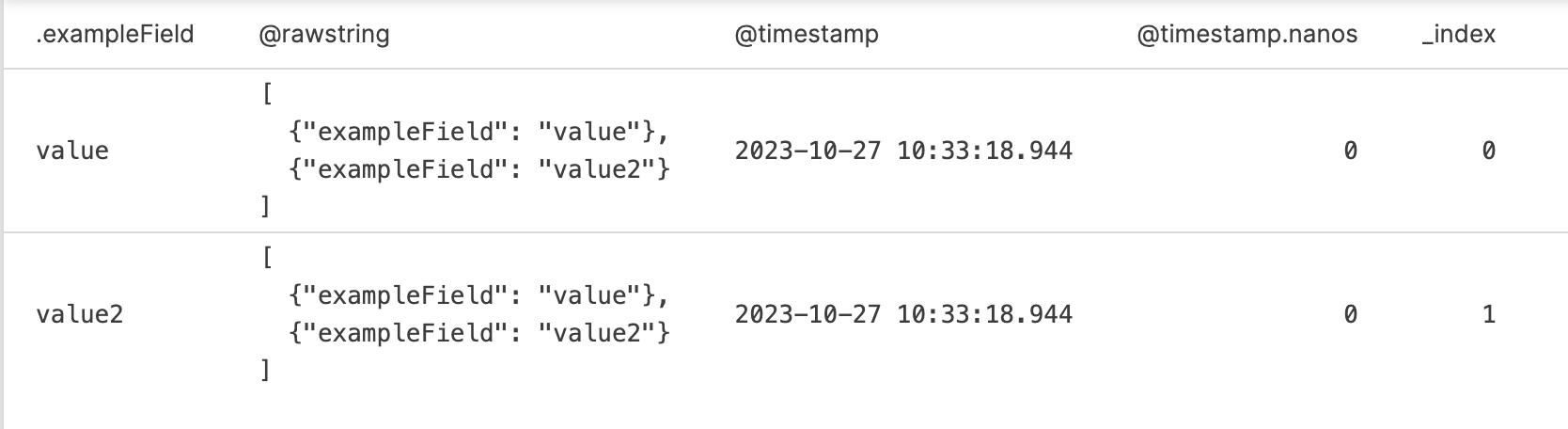
This means that parsing the above with:
parseJson()
| split(field="")
will produce two events, each with a field named
exampleField, and with
an additional field,
_index containing the
index (count) of the original data so that each individual
split() event can be identified:
 |
Alternatively, we can tell parseJson() to
add a prefix to all the fields, which can then use as the
field name to split on:
parseJson(prefix="example")
| split(field="example")
Unfortunately this adds the
example prefix to all fields
on the new event we've split out, so you may prefer splitting
on the empty field name to avoid that.
split() Examples
Click next to an example below to get the full details.
Deduplicate Compound Field Data
Simplifying compound fields into unique values using the
array:union() and
split() functions
Query
splitString(field=userAgent,by=" ",as=agents)
|array:filter(array="agents[]", function={bname=/\//}, var="bname")
|array:union(array=agents,as=browsers)
| split(browsers)Introduction
Deduplicating fields of information where there are multiple occurrences
of a value in a single field, maybe separated by a single character, can
be achieved in a variety of ways. This solution uses
array:union() and
splitString() create a unique array and then split
the content out to a unique list.
For example, when examining the humio and looking for the
browsers or user agents that have used your instance, the
UserAgent data will contain the
browser and toolkits used to support them, for example:
| Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 |
The actual names are the
Name/Version pairs showing
compatibility with different browser standards. Resolving this into a
simplified list requires splitting up the list, simplifying (to remove
duplicates), filtering, and then summarizing the final list.
Step-by-Step
Starting with the source repository events.
- logscale
splitString(field=userAgent,by=" ",as=agents)First we split up the userAgent field using a call to
splitString()and place the output into the array field agentsThis will create individual array entries into the agents array for each event:
agents[0] agents[1] agents[2] agents[3] agents[4] agents[5] agents[6] agents[7] agents[8] agents[9] agents[10] agents[11] agents[12] Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 - logscale
|array:filter(array="agents[]", function={bname=/\//}, var="bname") - logscale
|array:union(array=agents,as=browsers)Using
array:union()we aggregate the list of user agents across all the events to create a list of unique entries. This will eliminate duplicates where the value of the user agent is the same value.The event data now looks like this:
browsers[0] browsers[1] browsers[2] Gecko/20100101 Safari/537.36 AppleWebKit/605.1.15 An array of the individual values.
- logscale
| split(browsers)Using the
split()will split the array into individual events, turning:browsers[0] browsers[1] browsers[2] Gecko/20100101 Safari/537.36 AppleWebKit/605.1.15 into:
_index row[1] 0 Gecko/20100101 1 Safari/537.36 2 AppleWebKit/605.1.15 Event Result set.
Summary and Results
The resulting output from the query is a list of events with each event containing a matching _index and browser. This can be useful if you want to perform further processing on a list of events rather than an array of values.