
Deploying Prerequisites
Before starting deployment using Humio Operator and Kubernetes, the follow pre-requisite components should be installed and configured:
Prerequisites — Kafka and ZooKeeper
LogScale requires low latency access to a Kafka cluster to operate
optimally, you must have an available Kafka cluster before deploying
LogScale. Non-kafka systems that are similar are not supported, e.g.
Google PubSub or Azure EventHub are not supported. Sub 50 millisecond
ping times from the LogScale pods to the Kafka cluster will ensure data
is ingested quickly and be available for search in less than a second.
In its default configuration LogScale will automatically create the
Kafka topics and partitions required to operate. This functionality can
be disabled by setting the KAFKA_MANAGED_BY_HUMIO value
to false.
Running Kafka on Kubernetes can be accomplished a variety of ways. The Strimzi Kafka Operator is one such way and uses the same operator patterns that the Humio Operator uses to manage the life-cycles of both Kafka and ZooKeeper nodes. In production setups, LogScale, Kafka, and Zookeeper should be run on separate worker nodes in the cluster. Both Kafka and ZooKeeper must use persistent volumes provided by the Kubernetes environment, and they should not use ephemeral disks in a production deployment. Kafka brokers and ZooKeeper instances should be deployed on worker nodes in different locations such as racks, data centers, or availability zone to ensure reliability. Kubernetes operators such, as the Strimzi operator, do not create worker nodes and label them, that task is left to the administrators.
This yaml represents a basic Kafka cluster with 3 brokers, each running on worker nodes with 16 cores and 64GB of memory. The cluster is configured to have three replicas by default with the minimum in sync replicas set to two. This allows for the upgrading of brokers with no downtime as there will always be 2 brokers with the data. For more information on configuring Strimzi please see their documentation.
Operator Custom Resources
The operator overall supports two types of custom resources:
The first type makes it possible to manage a LogScale cluster by leveraging the CRD
HumioCluster. This will spin up and manage the cluster pods that makes up a LogScale cluster and the related Kubernetes resources to run the LogScale cluster.The second group of custom resources are focused on creating LogScale specific resources within LogScale clusters by using the LogScale API to manage them. At the time of writing, the humio-operator project supports the following CRDs for managing LogScale functionality:
HumioActionHumioAlertHumioIngestTokenHumioParserHumioRepositoryHumioView
Within the Kubernetes ecosystem it is very common to follow
GitOps-style
workflows. To help bridge the gap, even for clusters that aren't managed
by the humio-operator, there is a
HumioExternalCluster CRD. This CRD can be
configured with a URL and token to any LogScale cluster, that you may
want to manage e.g. alerts using "HumioAlert" resources on some cluster
where the cluster pods themselves are not managed by the
humio-operator. Since this uses the regular LogScale
APIs, this can also be used by customers to manage resources on the
LogScale cloud.
Basic Security and Resource Configuration
The following example provides the configuration for a basic cluster on AWS using ephemeral disks and bucket storage. Access to S3 is handled using IRSA (IAM roles for service accounts) and SSO is handled through a Google Workspace SAML integration (link). This example assumes IRSA and the Google Workspace are configured and can be provided in the configuration below.
Before the cluster is created the operator must be deployed to the Kubernetes cluster and three secrets created. For information regarding the installation of the operator please refer to the Install Humio Operator on Kubernetes.
Prerequisite secrets:
Bucket storage encryption key — Used for encrypting and decrypting all files stored using bucket storage.
SAML IDP certificate — Used to verify integrity during SAML SSO logins.
LogScale license key — Installed by the humio-operator during cluster creation. To update the license key for a LogScale cluster managed by humio-operator, this Kubernetes secret must be updated to the new license key. If updates to the license key is performed within the LogScale UI, it will be reverted to the license in this Kubernetes secret.
In practice it looks like this:
kubectl create secret --namespace example-clusters generic \
basic-cluster-1-bucket-storage --from-literal=encryption-key=$(openssl rand -base64 64)
kubectl create secret --namespace example-clusters generic \
basic-cluster-1-idp-certificate --from-file=idp-certificate.pem=./my-idp-certificate.pem
kubectl create secret --namespace example-clusters generic \
basic-cluster-1-license --from-literal=data=licenseStringOnce the secrets are created the following cluster specification can be applied to the cluster, for details on applying the specification see the operator resources Creating the Resource.
Once applied the HumioCluster resource is created
along with many other resources, some of which depend on
cert-manager. In the basic
cluster example a single node pool is created with three pods performing
all tasks.
The overall structure of the Kubernetes resources within a LogScale deployment looks like this:
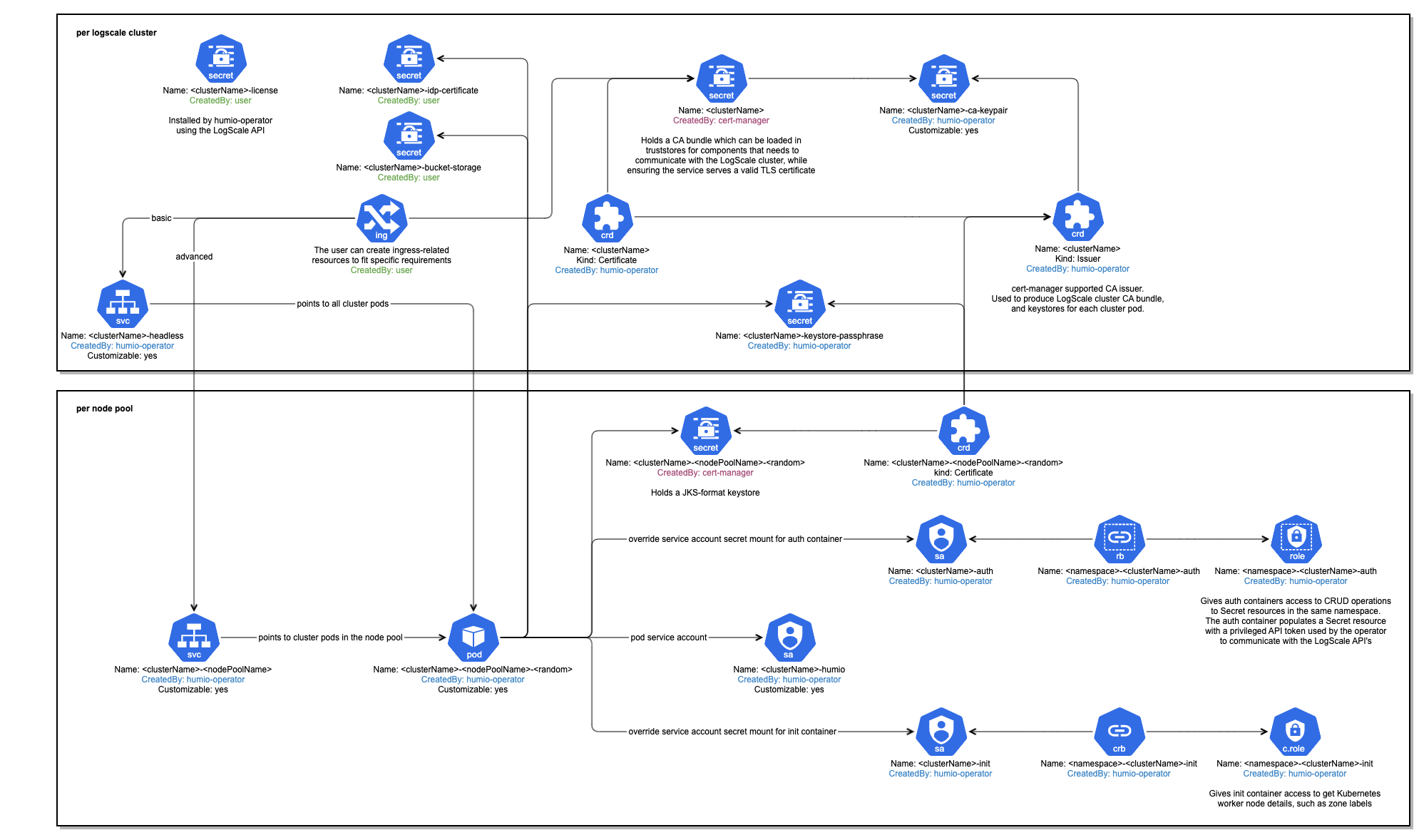 |
Figure 2. Kubernetes Installation Cluster Definition
Any configuration setting for LogScale can be used in the cluster specification. For additional configuration options please see the LogScale Configuration Parameters.
Ingress Configuration
The humio-operator contains one built-in ingress implementation, which relies on ingress-nginx to expose the cluster to the outside of the Kubernetes cluster. The built-in support for ingress-nginx should be seen mostly as a good starting point and source of inspiration, if it does not match certain requirements, it is possible to point alternative ingress controllers to the "Service" resource(s) pointing to the cluster pods. The built-in support for ingress-nginx only works if there is a single node pool with all nodes performing all tasks.
In most managed Kubernetes environment ingress has been integrated with the providers environment to orchestrate the creation of load balancers to load balance traffic to the LogScale service. In AWS when using the AWS Load Balancer Controller add-on (installation documentation) the following ingress object can be created to load balance external traffic to the basic-cluster service that was shown previously.
Basic Traefik IngressRoute example
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: logging
name: basic-cluster-ingress
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/healthcheck-path: /api/v1/status
alb.ingress.kubernetes.io/backend-protocol: HTTPS
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:xxxxxx:999999999999:certificate/xxxxxxxxx
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: basic-cluster-1
port:
number: 8080Pods running ingress can be scaled dynamically using the Kubernetes Horizontal Pod Autoscaler
Configuring Bucket Storage
Utilizing bucket storage allows the LogScale to operate on ephemeral disks. When an instance is replaced due to maintenance or hardware failure data will be pulled from object storage when a new instance replaces the old one. LogScale natively supports Amazon Bucket Storage and Google Bucket. S3 compatible systems such as MinIO are supported.
When LogScale determines segment files should be deleted, either by hitting retention settings or someone deleting a repository, the segments get marked for deletion, turning them into "tombstones". While they are marked for deletion, any local copies stored on the LogScale nodes will be deleted, but the copy stored in bucket storage will be kept around for a while before it gets deleted. By default, segments are kept for 7 days in bucket storage before the segment files gets deleted from bucket storage. This means it is possible to undo the deletion of segments as long as it is within 7 days of the segments being marked for deletion.
Configuring any type of quota on the bucket storage system is not recommended. LogScale assumes bucket storage will always be able to keep all the files it is trying to store in it.