
Bucket Storage
Security Requirements and Controls
Change S3 archiving settingspermission
LogScale supports writing a copy of the ingested logs to Amazon S3 and Google Cloud Storage using the native file format of LogScale, allowing LogScale to fetch those files and search them efficiently if the local copies are lost or deleted. This page will explain how to set up bucket storage with Amazon S3. For more details on this topic in general, see the Bucket Storage.
The files are encrypted by LogScale, as described under Security. For guidance on configuring encryption on Amazon S3, see Encryption of S3 Bucket Data.
Self-Hosting with S3
Bucket storage provides several significant features in LogScale. First, it makes cloud deployment of LogScale cheaper, faster, and easier to run using ephemeral disks as primary storage. It also enables recovery from the loss of multiple LogScale nodes without any data loss. New nodes can join the cluster by using just configuration, Kafka, and bucket storage. Plus, bucket storage allows you to keep more events than the local disks can hold, enabling unlimited retention.
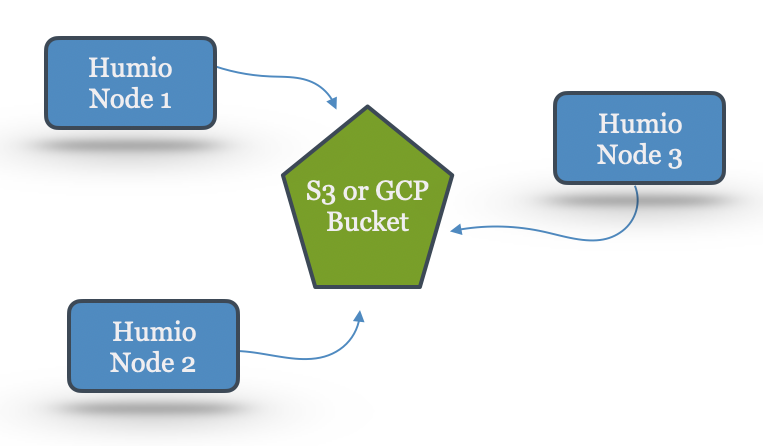 |
Figure 87. Bucket Storage
The copies written to the bucket are considered "safe" compared to a local copy as the bucket storage provided by S3 and GCP keep multiple copies in multiple locations. A bucket has unlimited storage and can hold an unlimited number of files. This allows the LogScale cluster to fetch the file from the provider in case of loss of node(s) that had the local copies. It also allows configuring LogScale for infinite retention by letting LogScale delete local files that are also in the bucket and fetch the data from the bucket once there is a request to search them.
LogScale manages the set of files in the bucket using the same
retention settings configured within LogScale for each repository.
LogScale will delete segment files in the bucket storage at the same
time as the segment file has been deleted in LogScale, taking into
account the configured backup interval as specified in the
DELETE_BACKUP_AFTER_MILLIS variable.
As a slight alternative, you may want to read the S3 Archiving page. It's about how to make LogScale export ingested events into S3 buckets in an open format readable by other applications, but not searchable in LogScale.
Bucket Storage with a Cluster in a Cloud Hosting Deployment
Bucket storage allows you to run LogScale without any persistent disks. In fact, doing so is encouraged when setting up the system this way, as persistent disks in a cloud environment require network traffic and that bandwidth is better put to use for bucket storage and for networking internally in the cluster.
Note
The Kafka cluster needs to be persistent and independent from the
LogScale cluster. It's also important to tell LogScale that the
disks are not to be relied upon as permanent storage by setting
USING_EPHEMERAL_DISKS to true so that LogScale
won't trust replicas supposedly present on other nodes in the
cluster, as they may vanish in this kind of environment.
Using network attached disks in combination with bucket storage is discouraged in cloud environments. Often you end up using much more network bandwidth this way.
Compression type should be set at "high" at level 9 (as is the default in 1.7.0 and later) to ensure that the files transferred to/from the bucket get as much compression applied as possible. This reduces the storage requirement both locally and in the bucket, reduces network traffic and improves search performance when data is not present locally.
When using ephemeral disks the choice of node ID needs selecting in
a controlled manner, and the strategy of storing it in the file
system no longer works. See the option
ZOOKEEPER_PREFIX_FOR_NODE_UUID in the configuration
page for a method of assigning unique node IDs to nodes using
ZooKeeper.
Combining the feature of "backup to a remote file system" and Bucket Storage is discouraged. Bucket storage replaces all functionality in the previous backup system.
Target Bucket
LogScale has the concept of a Target bucket, to which new files are uploaded. A node has a single target at any point in time. All buckets that have received a file at some point will get registered in "global" in the LogScale cluster. This allows any node in the cluster to fetch files from all buckets that have ever been a target for any node in the cluster.
Bucket storage should be configured for the entire cluster to ensure that all segment files get uploaded. There are no settings for individual repositories, and all data gets written to a single bucket. It is okay to switch to a fresh bucket at any point in time, also on a subset of the nodes, or in a rolling update fashion. A node uploads to the configured target bucket. Please note that the nodes will need to be able to fetch files from the previous target buckets for as long as there are files in them that they need to fetch. Do not delete or empty the previous target buckets. Make sure not to revoke any authentication tokens required for the reading of these existing files either. When a fresh target is configured, existing files do not get re-uploaded into that. The existing copy in the previous targets is the one it trusts.
High-Availability
It's possible to achieve high-availability of ingested events using this feature in combination with a Kafka installation that is not on the same file systems as the LogScale segment files. With LogScale set up to have multiple digest nodes for each partition, ingested events are either still in the ingest queue in Kafka, or on one of the LogScale nodes designated as digest node, or in the bucket storage. LogScale can resume from a combination of these after sudden and complete loss of a single LogScale node.
The local data storage directory holds the segment files as they get constructed. Once a segment file is complete, it gets uploaded to the bucket. Files copied to bucket storage also stay on the local disk in most cases. See Managing local disk space on how to allow LogScale to delete local files that also exist in the bucket.
LogScale also uploads the global-snapshot.json files to the bucket. This allows starting a node on an empty local data dir if there is a recent snapshot in the bucket configured as target for the node. The node then fetches the snapshot from the bucket and then gets up to date on the current state by reading global events from Kafka that have the changes since the snapshot was written.
For more information on the concept of segments files and datasources, see segments files and LogScale Internal Architecture.
One Node for Each Partition
It is possible to run with just one replica for both digest and storage. You must set USING_EPHEMERAL_DISKS=true in order to avoid the risk of data loss. When doing so, ingested data will remain in Kafka until it has been safely stored in the bucket. The loss of a node will be compensated for by the system, by assigning the digest or storage work to another live node.
You may prefer to configure 2 replicas for digest and storage however, as the system may operate more smoothly in the case of node failure. When there is only one replica of data outside the bucket, a failure of that node will cause that data to need fetching from the bucket in order to respond to queries.
Security
The copies in the bucket are optionally encrypted by LogScale using AES-256 while being uploaded to ensure that even if read access to the bucket is accidentally allowed, an attacker is not able to read any events or other information from the data in the files. The encryption key is based on the seed key string set in the configuration, and each file gets encrypted using a unique key derived from that seed.
Where the bucket service supports or enforces server-side encryption of bucket data with a service defined encryption key, secondary encryption by LogScale can be disabled.
The seed key is stored in global along with all the other information required to read and decrypt the files in that bucket. LogScale handles changes to the encryption seed key by keeping track of which files were encrypted using what secret.
LogScale computes a checksum of the local file (after encryption) while uploading and this checksum must match that computed by the receiver for the upload to complete successfully. This ensures that the bucket does not hold invalid or incomplete copies of the segment files.
To learn more about integrating services like Amazon AWS and Google Cloud into bucket storage with LogScale, see the documentation page on Amazon Bucket Storage or Google Bucket
Over-Committing Local Disk Space
LogScale can manage which segment files to keep on the local file system based on the amount of disk space used, and delete local files that also exist in bucket storage. This allows you to keep more data files than the local disk has room for, essentially allowing for infinite storage of events, at the cost of paying for S3 storage and (potentially) transfer costs when the files required for a search are not present on any node.
A copy in a bucket counts as a safe replica that allows the cluster to delete all local copies of the file and still report it as "perfectly replicated" from a cluster management perspective.
LogScale keeps track of which segment files are read by searches. When the disk is filled more than the desired percentage, LogScale will delete the least recently used segment files to free up disk space. Only files that have been copied to a bucket are ever removed.
If a file is not present locally and a search needs to read it, the search runs on all the parts that are present locally and schedules a download of the missing segment files from the bucket in the background. Once the required files arrive, they get searched as if they had been there from the start.
Files downloaded from the bucket to satisfy a search are kept in the secondary data directory if configured, or the primary data dir if no secondary is set. The downloaded segment files are treated like the recently created segment files, and are subject to the same rules regarding deleting them again when they become the least recently accessed file at some point.
Since LogScale can search the data at a much faster pace than the network and bucket storage provider can deliver them, the performance of searches that need files from the bucket provider will be orders of magnitude slower than searches that only access local files (on fast drives.) The good use case for over-committing the file system like this is to lower the cost of hosting LogScale trading in performance of searches in old events that happen to not be on the local disk.
The local file system needs to have room for at least accommodate all the mini segments and the most recent merged segments. Providing more local disk space allows LogScale to keep more files in the cache, resulting in better search performance.
Hash filter files are also stored in the bucket and also get downloaded when a search requires the segment file.
# Percentage of disk full that LogScale aims to keep the disk at.
# Segment files will be deleted in a least recently used order, in order to hit the configured fill target.
LOCAL_STORAGE_PERCENTAGE=80
# Minimum number of days to keep a fresh segment file before allowing
# it to get deleted locally after upload to a bucket.
# Setting such a lower bound can help ensure that recent files are kept on disk,
# even if they would otherwise be evicted due to queries on older data.
# Mini segment files are kept in any case until their merge result also exists.
# (The age is determined using the timestamp of the most recent event in the file)
# Make sure to leave most of the free space as room for the system to
# manage as a mix of recent and old files.
# Note! Min age takes precedence over the fill percentage, so increasing this
# implies the risk of overflowing the local file system!
LOCAL_STORAGE_MIN_AGE_DAYS=0Starting a New LogScale Cluster Based on Another with Buckets
Note
This is a feature for advanced users, requiring multiple independent Kafka clusters and buckets with careful management of these in order to not mix up targets.
LogScale supports a disaster recovery method based on bucket storage. The objects stored in the target bucket of a cluster can form the basis for bootstrapping a fully independent cluster. The new cluster needs to have a bucket of its own to store objects in, and will consider the "source" bucket as read only. It relies on the source bucket being immutable from the point the disaster recovery process starts - don't point to the bucket of another running LogScale cluster.
All example configs use S3_ as
prefix, use GCP_ if
applicable.
Common use cases for disaster recovery using this method include:
Recover a cluster to a working state after cluster failure.
Start a staging cluster for testing, based on data from a production cluster. This requires cloning the production cluster's bucket before starting, since the method requires the source bucket to be immutable during the recovery process.
Moving a cluster from one set of nodes to a fresh set. This requires the source cluster to run in ephemeral disk storage mode.
In all cases these are the steps that need to happen:
A single node in the target cluster must be started with an empty data dir
It must use a Kafka cluster where none of the LogScale topics exist, or those topics must be empty if you are manually managing topics. Use a fresh Kafka cluster or set a fresh prefix for the topic names.
It must not have access to a
global-data-snapshot.json. The recovery procedure only happens when there is no other snapshot to start from.It must have a target bucket for bucket storage that is empty.
It must have the configs
S3_RECOVER_FROM_*set for all the bucket storage target parameters otherwise namedS3_STORAGE_*` so that those refer to the bucket that it should start based on.It may have the configs
S3_RECOVER_FROM_REPLACE_REGIONandS3_RECOVER_FROM_REPLACE_BUCKETset to strings that are on the formsubstring/substitution. These allow you to make LogScale edit certain bucket settings in the global snapshot it loads from the source bucket, before it starts fetching other data. This way you can e.g. load a snapshot originally configured for region "us-west" in the source cluster, but have the target cluster read from a bucket copy in region "us-east".The new node may specify a new number of ingest partitions using
INGEST_QUEUE_INITIAL_PARTITIONSwhich will re-hash all datasources internally to the new number of partitions. This allows you to have different Kafka ingest partition counts in the source and target clusters.The new node should have whatever other configuration is required for the cluster (as a single node cluster for the moment) as the source cluster's configuration cannot be loaded from the source bucket.
The single new node starts by fetching the latest global snapshot file from the
S3_RECOVER_FROM_BUCKETand then rewrites that taking the following steps:Drop all hosts from the cluster, make the new cluster consist of just this single host that will be vhost node ID 1.
Rewrite both storage and digest partition tables to match a cluster of just this node.
Rewrite all segment entities to forget previous Kafka offsets and replace owner and current hosts, as those are not relevant anymore.
Create the required topics in Kafka (if allowed by configs)
Upload the resulting rewritten global snapshot to the new (so far empty) bucket storage target.
At this point you can access and inspect the new cluster using the single node if you want. Once you are satisfied that the cluster looks good, it is a good idea to remove the
S3_RECOVER_FROM_*settings from the node.Extend the cluster to the number of nodes you desire just as if this was any other LogScale cluster. The new nodes should not use the special recovery configuration.
The LogScale nodes will start fetching segment files from the "old" bucket and upload them to the new target, which will over time make the cluster have an independent copy of the full contents of the old bucket. Once this replication process completes, the new cluster no longer depends on any objects in the source bucket it was bootstrapped from, nor from other buckets that were referred in the snapshot fetched from that bucket.
In order for the recovery procedure to be lossless, the target cluster needs to get a global snapshot from the source cluster that does not reference segment files missing from the bucket. To create such a snapshot, the source cluster needs to be shut down gracefully before initiating the recovery procedure. This is typically not the case for an actual disaster recovery scenario, in which some data loss may be unavoidable, but for the migrate or clone cases it is doable. If the source cluster did not shut down gracefully, then there may be reports of missing segment files in the new target cluster. These can be resolved using the Missing Segments.
Decrypting Bucket Files Externally
LogScale provides a utility function to decrypt a file outside of LogScale that has been uploaded to the bucket by LogScale. This may come in handy as part of an audit process or as part of other processes that involve fetching files directly from the bucket. Usage:
java -cp humio.jar com.humio.main.DecryptAESBucketStorageFile <secret string> <encrypted file> <decrypted file>
Provide the path / filename of the input file to decrypt as
argument. The last part of the file name is included in the
decryption process, so file names must be preserved identical to
those in the bucket for the path after the last
/. The "secret string"
argument is the value of S3_STORAGE_ENCRYPTION_KEY /
GCP_STORAGE_ENCRYPTION_KEY that was in the LogScale
config at the time the file was uploaded by LogScale.
Important
When downloading the files on a macOS, be aware of the following conditions:
The filename when downloaded will include a period to separate the bucket and unique identifier for the file. This can be interpreted by macOS as a file extension. To prevent this, configure the Finder to use display full filenames. To do this, open Finder and and select → → → before downloading the files using the AWS console.
Files downloaded use a case-sensitive filename and may cause issues on an APFS volume that is not case sensitive.
Bucket Archived Log Re-ingestion
To re-ingest log data that has been written to an a bucket through archiving can be achieved by using LogScale Collector and the native JSON parsing within LogScale.
This process has the following requirements:
The files will need to be downloaded from the bucket to the machine running the LogScale Collector. The files cannot be accessed natively by the log collector.
The ingested events will be ingested into the repository that is created for the purpose of receiving the data.
To re-ingest logs this way:
Create a repo in LogScale where the ingested data will be stored. See Creating a Repository or View.
Create an ingest token, and choose the JSON parser. See Assigning Parsers to Ingest Tokens.
Install the Falcon LogScale Collector to read from a file using the
.gzextension as the file match. For example, using a configuration similar to this:yaml#dataDirectory is only required in the case of local configurations and must not be used for remote configurations files. dataDirectory: data sources: bucketdata: type: file # Glob patterns include: - /bucketdata/*.gz sink: my_humio_instance parser: json ...For more information, see Sources & Examples.
Copy the log file from the bucket into the configured directory (
/bucketdatain the above example.
The Log Collector will read the file that has been copied, send it to LogScale, where the JSON event data will be parsed and recreated.
Google Cloud Bucket Storage with Workload Identity
LogScale supports using Workload Identity for bucket storage and export to bucket of query results, rather than an explicit service account for Google Cloud Storage access.
To enable it, use the following configurations for bucket storage and export, respectively.
GCP_STORAGE_WORKLOAD_IDENTITY=trueGCP_EXPORT_WORKLOAD_IDENTITY=true
With these options enabled, the container service account will be used
for authentication rather than static keys. This configuration is
recommended as the best and most secure practice, therefore it takes
precedence over the usage of
GCP_STORAGE_ACCOUNT_JSON_FILE and
GCP_EXPORT_ACCOUNT_JSON_FILE settings.
Note
The account applied for export requires the
SignBlob project
level permission.