
Buckets & Archive Storage
Security Requirements and Controls
Change bucket storagepermission
Data that comes into a repository is generally stored locally, on the server where LogScale and the repository is located. Eventually, you may accumulate and retain too much data, including old data that you don't often search. At a minimum, this will affect LogScale performance when searching more current data. You also risk losing part or all of the data, should your server crash when running LogScale on a single server.
First, you might simple establish a system to delete old data. Another remedy is to use LogScale in a cluster of nodes. That generally improves performance and allows for redundancy of data. A simpler method is to make use of external storage. This may be used in addition to a cluster and as a part of it.
There are several methods and factors related to storing LogScale data that you might consider. Below are links to pages describing the different methods and related topics.
So that servers don't reach their maximum storage capabilities, you can set LogScale to delete data based on compressed file sizes, uncompressed file sizes, and based on age of data. Click on the heading here to read more on data retention.
Secondary storage is a way to keep the local drives from reaching capacity. When enabled, LogScale will move segment files to secondary storage once the primary disk reaches whatever limit you set.
Similar to secondary storage, but utilizes specialized storage with web service providers like Amazon Bucket Storage Google Bucket. Bucket storage is particularly useful, though, in a cluster in that it makes deployment of nodes easier and helps to maintain back-ups in case a node or a cluster crashes.
Ingested logs may be archived to Amazon S3. LogScale won't be able to search that data, though. However, the data may accessed by any external system that integrates with S3.
Before going any further, you should familiarize yourself with LogScale's storage rules, which is covered in the next section here.
Storage Rules
In LogScale, data is distributed across the cluster nodes. Which nodes store what is chosen randomly. The only thing you as an operator can control is how big a portion is assigned to each node, and that multiple replicas are not stored on the same rack/machine/location (to ensure fault-tolerance).
Data is stored in units of
segments, which are compressed
files between 0.5GB and 1GB.
See LogScale Multiple-byte Units for more information on how storage numbers are calculated.
Replication Factor
If you want fault-tolerance, you should ensure your data is replicated across multiple nodes, physical servers, and geographical locations.
You can achieve this by setting the storage replication factor higher than 1, and configuring ZONE on your nodes. LogScale uses your ZONE node configuration to determine where to place data, we will always place data in as many ZONEs as possible.
UI for Storage Nodes
From your account profile menu, select
In the
System Administrationpage → Cluster nodes tab, check the storage displayed under Replication:
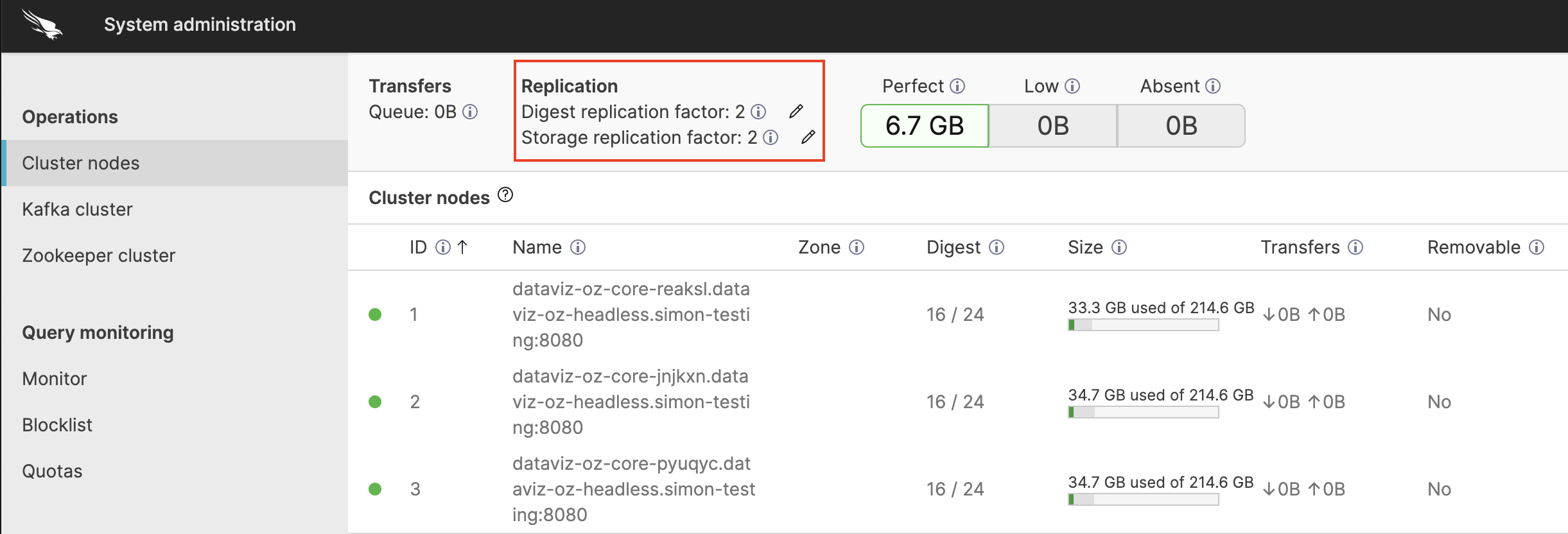 |
Figure 83. UI for Storage Nodes
The figure above shows a cluster of 3 nodes where each node is assigned to 2 archive partitions leading to a replication factor of 2.
Storage Divergence
LogScale is capable of storing and searching across huge amounts of data. When LogScale Operational Architecture join or leave the cluster, data will usually need to be moved between nodes to ensure the replication factor is upheld and that no data is lost.
LogScale automatically redistributes data when nodes go offline, ensuring that your configured replication factor is met. This movement of data is throttled, to avoid excessively loading the cluster when a node goes offline. The "Low" counter will show a non-zero number while data is not replicated properly, letting you tell whether this movement of data is complete.
A Node is Removed Uncleanly
If you know ahead of time that you want to Adding & Removing Nodes from the cluster, you can reduce the impact on the cluster by first evicting the node. Eviction will migrate work off of the node, and move data from the evicted node to other nodes.
Storage Metrics within the LogScale UI - Cluster Stats
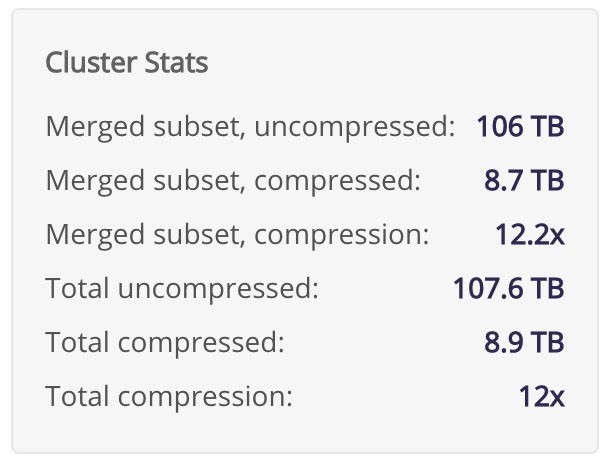 |
Figure 84. Cluster Stats
These metrics are applicable to both cluster and single node installations.
On the front page of LogScale, there is a Cluster Stats box that gives you information regarding how much data is in the cluster. These storage statistics are meant to represent the searchable data within LogScale. This indicates it includes the compressed ingested data that is found within LogScale segment files. It also means it includes LogScale's own system data, but does not include the duplicated or replicated data.
Storage Metrics within the LogScale UI - Cluster Nodes
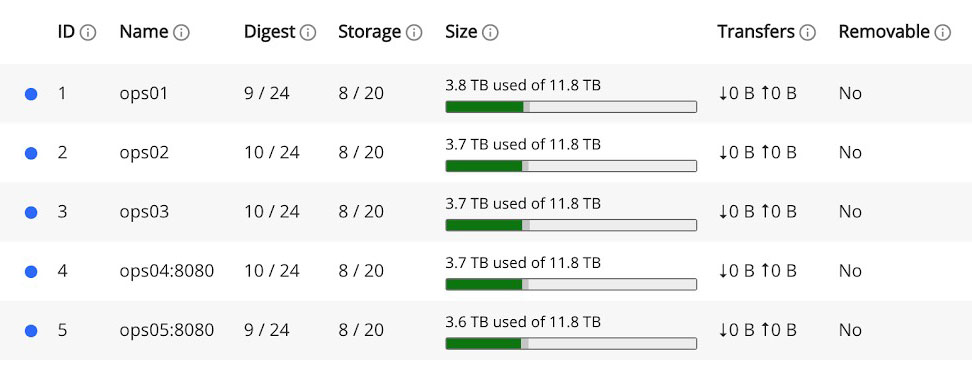 |
Figure 85. Cluster Nodes
Under the Cluster Administration tab, you can see the list of LogScale nodes that display Size information: the green part of this bar is 'LogScale Data'; the darker grey is all your other data on that node; and the lighter grey is free space.
What LogScale Data means is this context is that it includes the compressed ingested data that is found within LogScale segment files. It means that it also includes the duplicated or replicated data, but doesn't include LogScale's own system data.
Storage Metrics within the LogScale UI - Cluster Administration
 |
Figure 86. Cluster Administration
Under the Cluster Administration tab at
the top of the page under
Replication, you can find
information regarding your Replication. Perfect means the total size
of segment files that meet the replication factor.
Low is the total size of the segment files that
are less than the replication factor. Absent
means LogScale knows about these segment files but can't find them on
any of the nodes.
The total size that is displayed within these boxes includes the compressed ingested data that is found within LogScale segment files. It doesn't include additional duplicated or replicated data. Nor does it include LogScale's own system data.