

S3 Archiving (Self-Install)
Security Requirements and Controls
Change S3 archiving settingspermission
LogScale supports archiving ingested logs to Amazon S3. The archived logs are then available for further processing in any external system that integrates with S3. The files written by LogScale in this format are not searchable by LogScale — this is an export meant for other systems to consume. See Amazon Bucket Storage or Google Bucket for using S3 as storage for segments in a format that LogScale can read.
When S3 Archiving is enabled all the events in repository are backfilled into S3 and then it archives new events by running a periodic job inside all LogScale nodes, which looks for new, unarchived segment files. The segment files are read from disk, streamed to an S3 bucket, and marked as archived in LogScale.
An admin user needs to set up archiving per repository. After selecting a repository on the LogScale front page, the configuration page is available under Settings.
Note
For slow-moving datasources it can take some time before segment files are completed on disk and then made available for the archiving job. In the worst case, before a segment file is completed, it must contain a gigabyte of uncompressed data or 30 minutes must have passed. The exact thresholds are those configured as the limits on mini segments.
Important
S3 archiving is not supported for S3 buckets where object locking is enabled.
For more information on segments files and datasources, see segments files and LogScale Internal Architecture.
S3 Archiving Storage Format and Layout
When uploading a segment file, LogScale creates the S3 object key based on the tags, start date, and repository name of the segment file. The resulting object key makes the archived data browseable through the S3 management console.
LogScale uses the following pattern:
REPOSITORY/TYPE/TAG_KEY_1/TAG_VALUE_1/../TAG_KEY_N/TAG_VALUE_N/YEAR/MONTH/DAY/START_TIME-SEGMENT_ID.gzWhere:
REPOSITORYName of the repository
typeKeyword (static) to identfy the format of the enclosed data.
TAG_KEY_1Name of the tag key (typically the name of parser used to ingest the data, from the #type field)
TAG_VALUEValue of the corresponding tag key.
YEARYear of the timestamp of the events
MONTHMonth of the timestamp of the events
DAYDay of the timestamp of the events
START_TIMEThe start time of the segment, in the format
HH-MM-SSSEGMENT_IDThe unique segment ID of the event data
Read more about Event Tags.
Format
LogScale supports two formats for storage, native format and NDJSON.
Native Format
The native format is the raw data, i.e. the equivalent of the @rawstring of the ingested data:
accesslog127.0.0.1 - - [07/Mar/2023:15:09:42 +0000] "GET /falcon-logscale/css-images/176f8f5bd5f02b3abfcf894955d7e919.woff2 HTTP/1.1" 200 15736 "http://localhost:81/falcon-logscale/theme.css" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36" 127.0.0.1 - - [07/Mar/2023:15:09:43 +0000] "GET /falcon-logscale/css-images/alert-octagon.svg HTTP/1.1" 200 416 "http://localhost:81/falcon-logscale/theme.css" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36" 127.0.0.1 - - [09/Mar/2023:14:16:56 +0000] "GET /theme-home.css HTTP/1.1" 200 70699 "http://localhost:81/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36" 127.0.0.1 - - [09/Mar/2023:14:16:59 +0000] "GET /css-images/help-circle-white.svg HTTP/1.1" 200 358 "http://localhost:81/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36" 127.0.0.1 - - [09/Mar/2023:14:16:59 +0000] "GET /css-images/logo-white.svg HTTP/1.1" 200 2275 "http://localhost:81/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"NDJSON Format
The default archiving format is NDJSON When using NDJSON, the parsed fields will be available along with the raw log line. This incurs some extra storage cost compared to using raw log lines but gives the benefit of ease of use when processing the logs in an external system.
json{"#type":"kv","#repo":"weblog","#humioBackfill":"0","@source":"/var/log/apache2/access_log","@timestamp.nanos":"0","@rawstring":"127.0.0.1 - - [07/Mar/2023:15:09:42 +0000] \"GET /falcon-logscale/css-images/176f8f5bd5f02b3abfcf894955d7e919.woff2 HTTP/1.1\" 200 15736 \"http://localhost:81/falcon-logscale/theme.css\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36\"","@id":"XPcjXSqXywOthZV25sOB1hqZ_0_1_1678201782","@timestamp":1678201782000,"@ingesttimestamp":"1691483483696","@host":"ML-C02FL14GMD6V","@timezone":"Z"} {"#type":"kv","#repo":"weblog","#humioBackfill":"0","@source":"/var/log/apache2/access_log","@timestamp.nanos":"0","@rawstring":"127.0.0.1 - - [07/Mar/2023:15:09:43 +0000] \"GET /falcon-logscale/css-images/alert-octagon.svg HTTP/1.1\" 200 416 \"http://localhost:81/falcon-logscale/theme.css\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36\"","@id":"XPcjXSqXywOthZV25sOB1hqZ_0_3_1678201783","@timestamp":1678201783000,"@ingesttimestamp":"1691483483696","@host":"ML-C02FL14GMD6V","@timezone":"Z"} {"#type":"kv","#repo":"weblog","#humioBackfill":"0","@source":"/var/log/apache2/access_log","@timestamp.nanos":"0","@rawstring":"127.0.0.1 - - [09/Mar/2023:14:16:56 +0000] \"GET /theme-home.css HTTP/1.1\" 200 70699 \"http://localhost:81/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36\"","@id":"XPcjXSqXywOthZV25sOB1hqZ_0_15_1678371416","@timestamp":1678371416000,"@ingesttimestamp":"1691483483696","@host":"ML-C02FL14GMD6V","@timezone":"Z"} {"#type":"kv","#repo":"weblog","#humioBackfill":"0","@source":"/var/log/apache2/access_log","@timestamp.nanos":"0","@rawstring":"127.0.0.1 - - [09/Mar/2023:14:16:59 +0000] \"GET /css-images/help-circle-white.svg HTTP/1.1\" 200 358 \"http://localhost:81/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36\"","@id":"XPcjXSqXywOthZV25sOB1hqZ_0_22_1678371419","@timestamp":1678371419000,"@ingesttimestamp":"1691483483696","@host":"ML-C02FL14GMD6V","@timezone":"Z"} {"#type":"kv","#repo":"weblog","#humioBackfill":"0","@source":"/var/log/apache2/access_log","@timestamp.nanos":"0","@rawstring":"127.0.0.1 - - [09/Mar/2023:14:16:59 +0000] \"GET /css-images/logo-white.svg HTTP/1.1\" 200 2275 \"http://localhost:81/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36\"","@id":"XPcjXSqXywOthZV25sOB1hqZ_0_23_1678371419","@timestamp":1678371419000,"@ingesttimestamp":"1691483483696","@host":"ML-C02FL14GMD6V","@timezone":"Z"}A single NDJSON line is just a JSON object, which formatted looks like this:
json{ "#humioBackfill" : "0", "#repo" : "weblog", "#type" : "kv", "@host" : "ML-C02FL14GMD6V", "@id" : "XPcjXSqXywOthZV25sOB1hqZ_0_1_1678201782", "@ingesttimestamp" : "1691483483696", "@rawstring" : "127.0.0.1 - - [07/Mar/2023:15:09:42 +0000] \"GET /falcon-logscale/css-images/176f8f5bd5f02b3abfcf894955d7e919.woff2 HTTP/1.1\" 200 15736 \"http://localhost:81/falcon-logscale/theme.css\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36\"", "@source" : "/var/log/apache2/access_log", "@timestamp" : 1678201782000, "@timestamp.nanos" : "0", "@timezone" : "Z" }
Setup
For a self-cloud installation of LogScale, you need an IAM user with write access to the buckets used for archiving. That user must have programmatic access to S3, so when adding a new user through the AWS console make sure programmatic access is ticked:
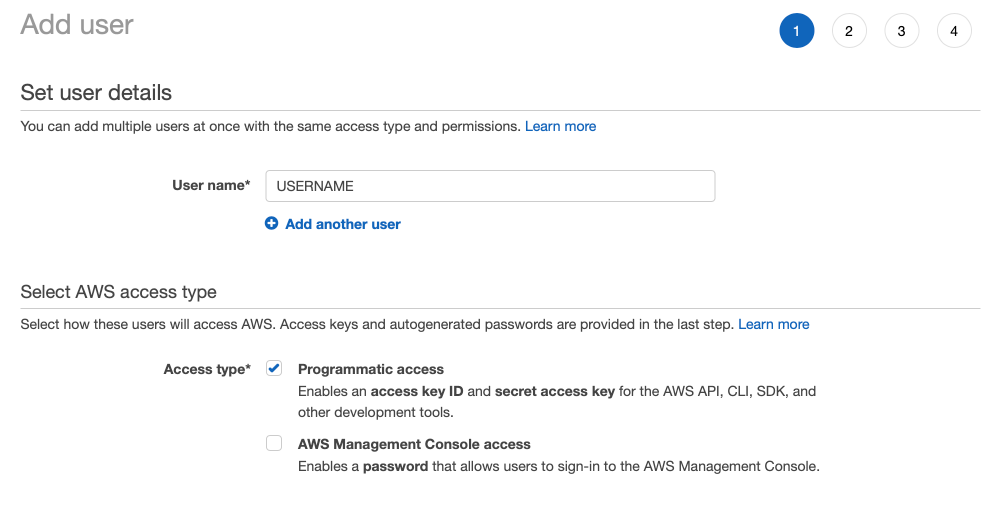 |
Figure 91. Setup
Later in the process, you can retrieve the access key and secret key:
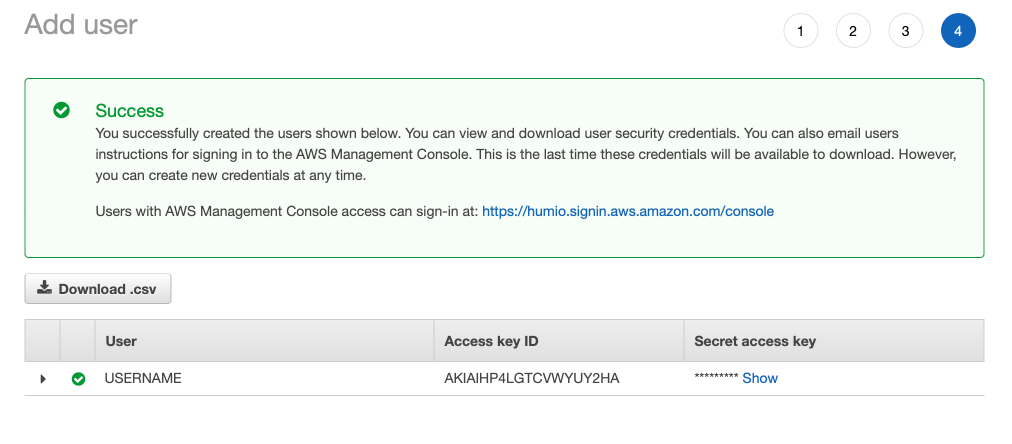 |
Figure 92. Setup Key
This is needed in LogScale in the following configuration:
S3_ARCHIVING_ACCESSKEY=$ACCESS_KEY
S3_ARCHIVING_SECRETKEY=$SECRET_KEYThe keys are used for authenticating the user against the S3 service. For more guidance on how to retrieve S3 access keys, see AWS access keys. For more details on creating a new user, see creating a new user in IAM.
Configuring the user to have write access to a bucket can be done by attaching a policy to the user.
IAM user example policy
The following JSON is an example policy configuration.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::BUCKET_NAME"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::BUCKET_NAME/*"
]
}
]
}The policy can be used as an inline policy attached directly to the user through the AWS console:
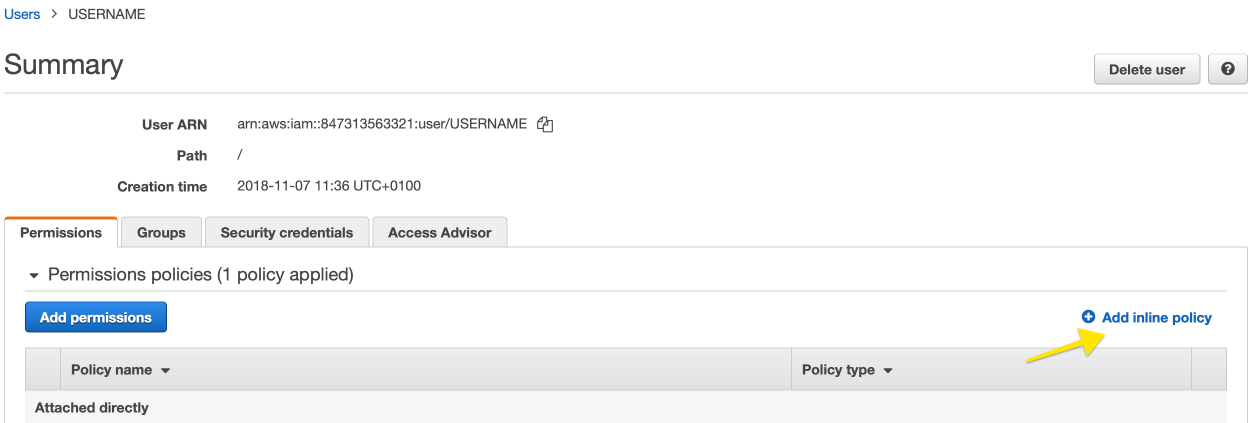 |
Figure 93. IAM user example policy
Tag Grouping
If tag grouping is defined for a repository, the segment files will be split by each unique combination of tags present in a file. This results in a file in S3 per each unique combination of tags. The same layout pattern is used as in the normal case. The reason for doing this is to make it easier for a human operator to determine whether a log file is relevant.
Other Options
HTTP Proxy
If LogScale is set up to use an HTTP_PROXY_HOST, it
will per default be used for communicating with S3. It can be
disabled using the following:
# Use the globally configured HTTP proxy for communicating with S3.
# Default is true.
S3_ARCHIVING_USE_HTTP_PROXY=falseNon-default endpoints
You can point to your own hosting endpoint for the S3 to use for archiving if you host an S3-compatible service like MinIO.
S3_ARCHIVING_ENDPOINT_BASE=http://my-own-s3:8080Virtual host style (default)
LogScale will construct virtual host-style URLs like
https://my-bucket.my-own-s3:8080/path/inside/bucket/file.txt.
For this style of access, you need to set your base URL, so it contains a placeholder for the bucket name.
S3_ARCHIVING_ENDPOINT_BASE=http://{bucket}.my-own-s3:8080
LogScale will replace the placeholder
{bucket} with the relevant bucket
name at runtime.
Path-style
Some services do not support virtual host style access, and
require path-style access. Such URLs have the format
https://my-own-s3:8080/my-bucket/path/inside/bucket/file.txt.
If you are using such a service, your endpoint base URL should
not contain a bucket placeholder.
S3_ARCHIVING_ENDPOINT_BASE=http://my-own-s3:8080
Additionally, you must set
S3_ARCHIVING_PATH_STYLE_ACCESS to true.
IBM Cloud Storage compatibility
S3 Archiving can be used with IBM Cloud Storage by setting
S3_ARCHIVING_IBM_COMPAT to true.