
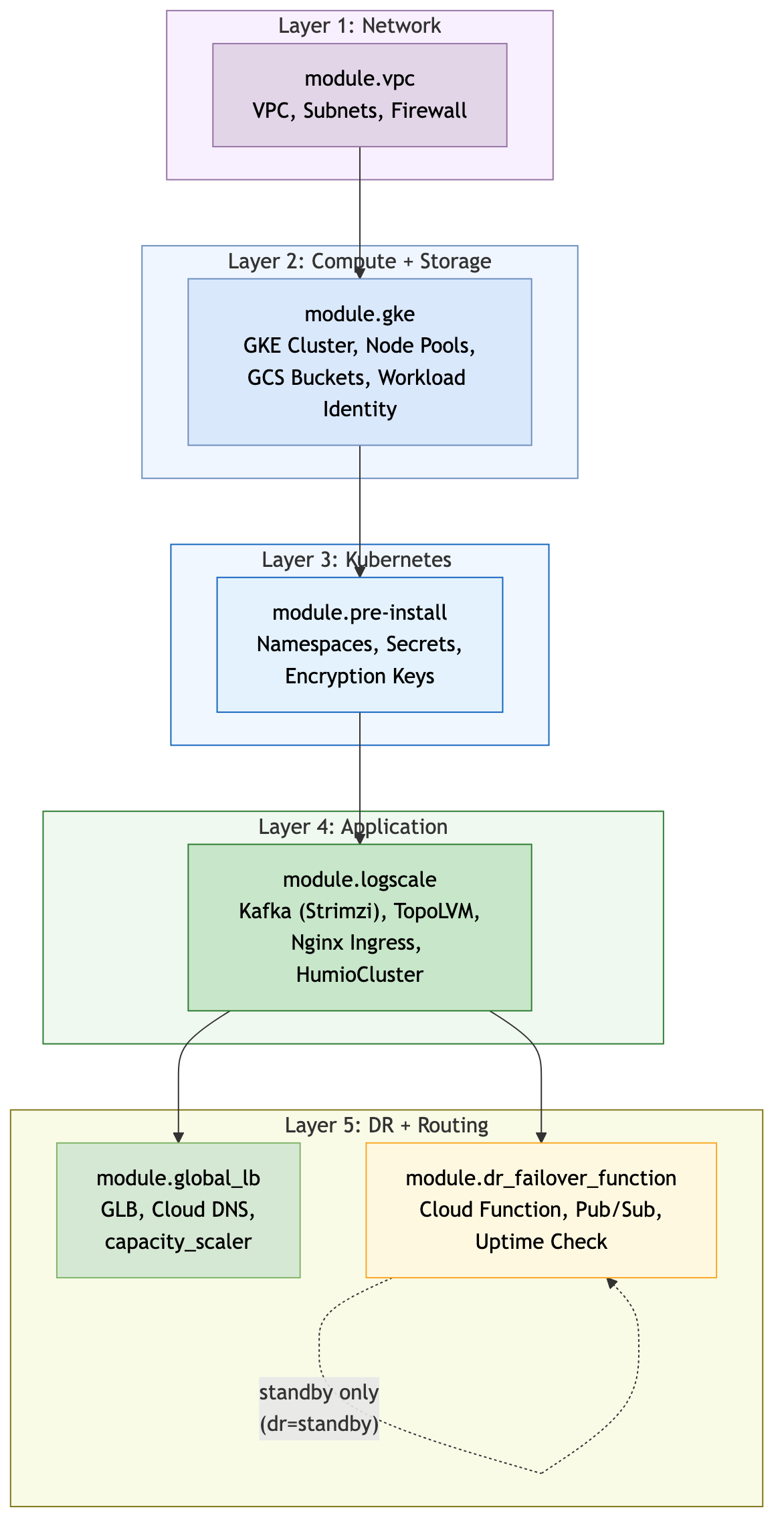
Failover Function Details
The DR failover Cloud Function is the core automation component that scales the humio-operator deployment when the primary cluster fails.
 |
Uptime Checks
GCP Uptime Checks monitor the primary LogScale endpoint:
| Uptime Check | Target | Protocol | Path | Interval |
|---|---|---|---|---|
| Primary |
<primary-hostname>.<zone-name>
| HTTPS | /api/v1/status | 60s |
Global DNS Record:
Global hostname:
<global-hostname>.<zone-name>Routing: Global Load Balancer with
capacity_scaler-basedfailoverPrimary: Backend with
capacity_scaler=1.0(health check gated)Secondary: Backend with
capacity_scaler=0.0(failover target)
Cloud Monitoring Alert
A Cloud Monitoring alert policy monitors the primary Uptime Check and triggers the failover pipeline when the primary becomes unhealthy.
Configuration:
Resource name:
google_monitoring_alert_policy.dr_failover_alertDisplay name:
${cluster_name}DR Failover AlertMetric:
monitoring.googleapis.com/uptime_check/check_passedAligner:
ALIGN_NEXT_OLDERwithREDUCE_COUNT_FALSE(counts false check results)Condition: Count of false < 1 for 60-second alignment period
Missing data: Treated as failing (fail-safe)
Action: Publishes to Pub/Sub topic when alert triggers
resource "google_monitoring_alert_policy" "dr_failover_alert" {
display_name = "${var.cluster_name} DR Failover Alert"
combiner = "OR"
conditions {
display_name = "Primary cluster uptime check failure"
condition_threshold {
filter = "resource.type=\"uptime_url\" AND metric.type=\"monitoring.googleapis.com/uptime_check/check_passed\" AND metric.labels.check_id=\"${...uptime_check_id}\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 1
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_NEXT_OLDER"
cross_series_reducer = "REDUCE_COUNT_FALSE"
group_by_fields = ["resource.label.project_id"]
}
}
}
notification_channels = [google_monitoring_notification_channel.dr_pubsub[0].id]
}Pub/Sub Topic
A Pub/Sub topic bridges the Cloud Monitoring alert to the Cloud Function:
Name:
${cluster_name}-dr-alertsPublisher: Cloud Monitoring alert policy (via
dr_pubsubnotification channel)Subscriber: Cloud Function (EventArc trigger,
google.cloud.pubsub.topic.v1.messagePublished)
Cloud Function Internals
The DR failover Cloud Function
(${cluster_name}-dr-failover) is deployed as a Cloud
Functions v2 (Gen2) function backed by Cloud Run. It is triggered by the
Pub/Sub topic via EventArc and executes with a dedicated service account
(dr_function_sa).
Execution Steps
When triggered by a Pub/Sub message from the Cloud Monitoring alert, the function executes:
Cooldown Check: Reads cooldown state from GCS bucket (
COOLDOWN_STATE_BUCKET) to verify sufficient time has passed since the last failover (configurable viaFAILOVER_COOLDOWN_SECONDS, default: 300 seconds)Pre-Failover Validation: Queries Cloud Monitoring to confirm primary has been failing for the configured duration (
PRE_FAILOVER_FAILURE_SECONDS, default: 180 seconds). IfSKIP_PRIMARY_HEALTH_VALIDATION=true, this step is bypassed.Secondary Cluster Health Check: Verifies the secondary GKE cluster is reachable and healthy before proceeding. Failover aborts if the secondary cluster is unreachable.
GKE Authentication: Uses the function's service account to authenticate to the secondary GKE cluster (
CLUSTER_NAMEinCLUSTER_LOCATION)Idempotency Check: Reads current humio-operator replica count (skips if already scaled up)
TLS Secret Cleanup: Deletes the stale cluster TLS secret to prevent CA certificate mismatch errors
Operator Scaling: Patches the humio-operator deployment from 0 to
TARGET_NODE_COUNTreplicasCooldown State Persist: Writes cooldown timestamp to GCS bucket
GLB Capacity Scaler Update: Updates the GLB backend service (
GLB_BACKEND_SERVICE_NAME) to flipcapacity_scalervalues — secondary to 1.0, primary to 0.0 — preventing failback when primary recovers
Key Point: The Cloud Function scales the humio-operator deployment and
flips the GLB capacity_scaler. The operator then
reconciles the HumioCluster CR (which already declares
nodeCount=1) and starts the LogScale pod. The function does
NOT modify the HumioCluster spec.
Pre-Failover Validation
The Cloud Function includes critical validation to prevent false failovers:
| Check | Purpose | Default |
|---|---|---|
| Consecutive Failure Duration | Confirms primary has been failing continuously, not just a brief blip |
180 seconds (PRE_FAILOVER_FAILURE_SECONDS)
|
| Current Health Status |
Re-checks Uptime Check
(PRIMARY_UPTIME_CHECK_ID) to ensure primary
hasn't recovered since alert triggered
| Always checked |
| Cooldown Period | Prevents rapid failover/failback cycles that could cause instability |
300 seconds (default, configurable via
FAILOVER_COOLDOWN_SECONDS, default: 300
seconds)
|
Retry Logic
All Kubernetes API operations use exponential backoff with jitter:
| Parameter | Default | Description |
|---|---|---|
MAX_RETRIES
| 3 | Maximum retry attempts per operation |
BASE_DELAY_SECONDS
| 1.0 | Initial delay before first retry |
MAX_DELAY_SECONDS
| 30.0 | Maximum delay cap between retries |
Cloud Function Environment Variables
The Cloud Function receives the following environment variables from Terraform:
# Target cluster configuration
PROJECT_ID = <gcp-project-id>
CLUSTER_NAME = <secondary-cluster-name>
CLUSTER_LOCATION = <secondary-cluster-region>
NAMESPACE = <logscale-namespace>
TARGET_NODE_COUNT = <target-operator-replicas>
HUMIOCLUSTER_NAME = <humiocluster-resource-name>
# Health validation
PRIMARY_UPTIME_CHECK_ID = <uptime-check-id>
SKIP_PRIMARY_HEALTH_VALIDATION = false
# Retry configuration
MAX_RETRIES = 3
BASE_DELAY_SECONDS = 1
MAX_DELAY_SECONDS = 30
# Pre-failover validation
PRE_FAILOVER_FAILURE_SECONDS = 180
FAILOVER_COOLDOWN_SECONDS = <cooldown-seconds>
# GLB failback prevention
GLB_BACKEND_SERVICE_NAME = <glb-backend-service-name>
# Cooldown state persistence
COOLDOWN_STATE_BUCKET = <dr-function-source-bucket>