
Cluster Topologies
This section illustrates some recommended cluster topologies. Reference architectures are based on these validated architectures. There are three main topolgies that will be presented:
Simple - Symmetric cluster - All nodes have all roles
Medium - Cluster with HTTP handling nodes
Advanced - Cluster with multiple different nodes
Designing a cluster topology often involves the following tradeoffs:
Simplicity versus complexity
Isolation versus shared resources
Fault tolerance versus hardware cost
Scaling workloads independently versus hardware costs and elasticity of the system
Different machines for different workloads
CPU, memory, disks, network, virtualization
How is the system deployed?
How are new versions rolled out?
Note
This section assumes you are familiar with the LogScale architecture documentation.
Simple - Symmetric Cluster
In this topology all machines are identical and run all roles. It is a simple symmetrical setup where all machines are configured the same way, both in terms of software configuration and hardware specs. The hardware running Kafka and (on-premises) bucket storage will typically be different.
Workloads are shared and all machines participate in all the workloads. That can be very cost efficient and allow for some elasticity in handling spiking workloads. If there is a spike in ingest data the workloads for ingest, parsing and digest will increase and all machines can participate and use their resources.
Typically search workloads are not uniform and consistent. People log in, do a lot of searching (dashboards) and end their session. When no search is being performed, the resources that would otherwise be used for searching (storage nodes) can be used to handle ingest spikes.
The downside to this approach is that a rogue client can impact all nodes by overloading the cluster with ingest data. Also, a faulty parser might consume too many resources and overload all nodes. If workloads were isolated on a subset of machines, problems such as these are less likely to impact the whole cluster.
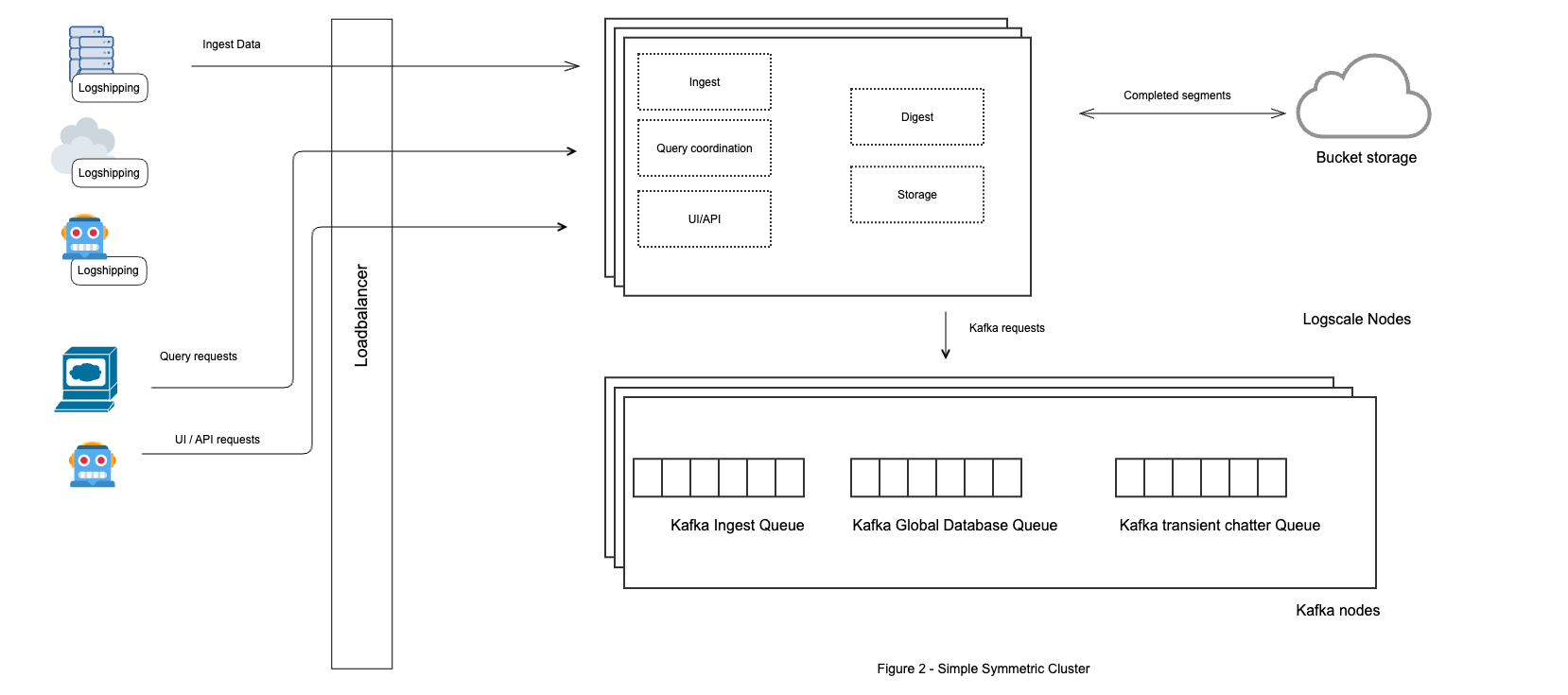 |
Figure 72. Simple Cluster Topology
Medium - Cluster with HTTP handling nodes
This cluster topology has two different types of nodes: frontend HTTP nodes and backend nodes. Frontend nodes receive all external requests and process ingest, query coordination, and handling of UI/API requests. Backend nodes process digest, storage, and search requests.
The backend nodes are typically machines with fast disks, substantial memory, and many cores. Frontend nodes can be more lightweight, with less storage capacity. Frontend nodes are stateless (although query coordination is partially stateful).
Compared to the symmetrical cluster topology there is some workload isolation. Backend nodes cannot be reached from the outside and are protected from problems such as errant clients or huge spikes in ingest requests. Search workloads are also isolated to the backend machines and will not impact ingestion. The frontend nodes do the query coordination but no data is searched on those nodes.
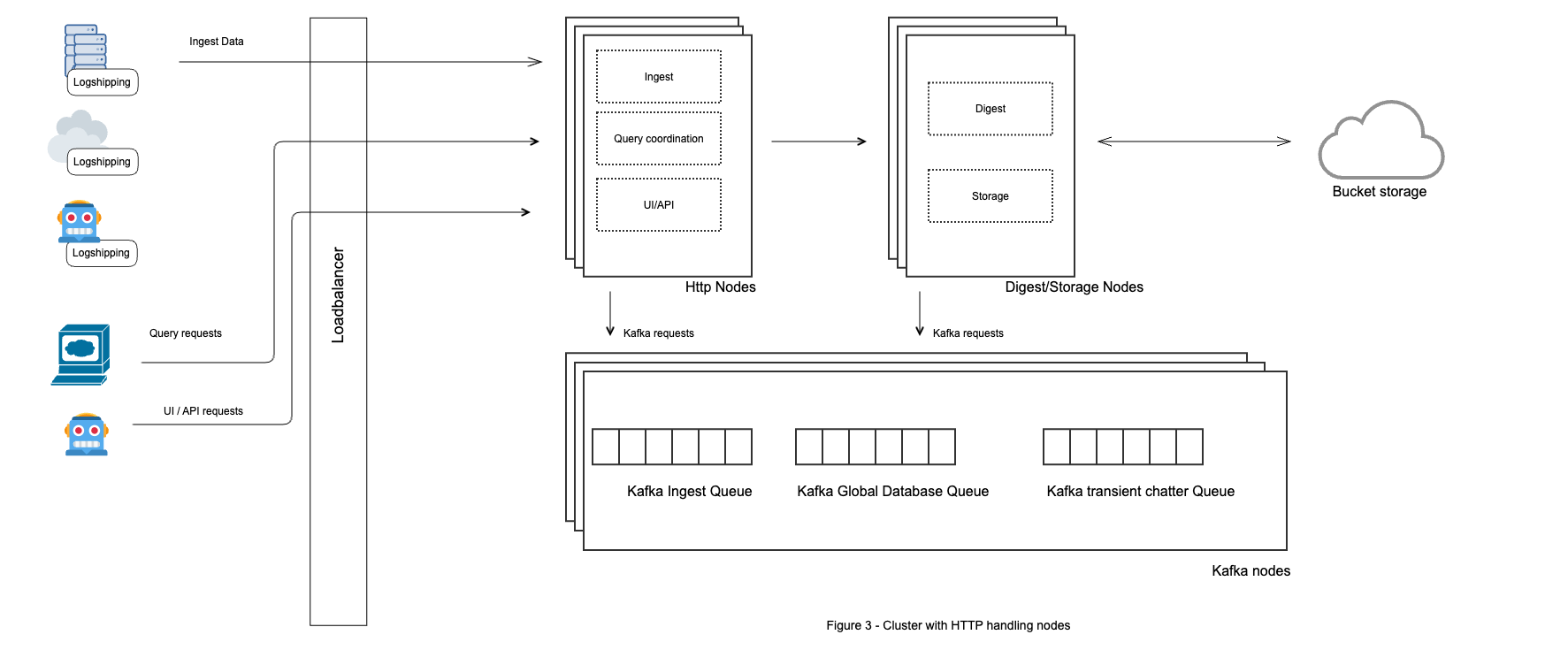 |
Figure 73. Medium Cluster Topology
Advanced - Cluster with multiple different nodes
In this topology all roles are separated out on to different nodes.
There are multiple variants of this setup:
Running all roles on separate machines as shown in the diagram below.
Combining digest and storage roles on machines. This works if the nodes are high performance machines with large disks. The same CPU resources are shared between digest, live searches, and historical searches. Disks on these machines hold both mini-segments from the digest processing, as well as the larger segments.
It is possible to organize the frontend roles (Ingest, Query coordination, and UI/API) on separate machines as needed.
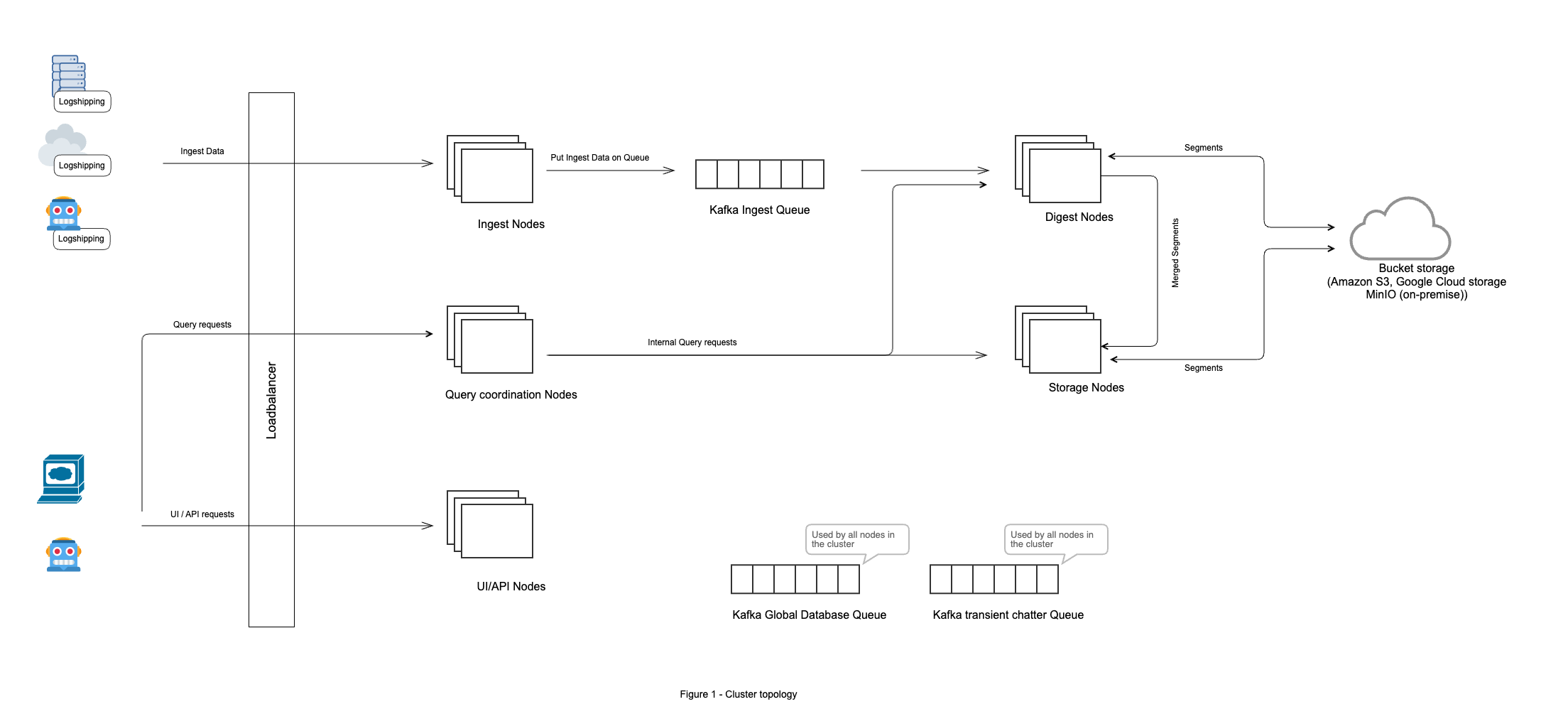 |
Figure 74. Advanced Cluster Topology
The follow sections discuss some trade-offs for the various ways of separating out roles onto specific nodes.
Separate digest and storage nodes
Digest and storage roles can be put on the same nodes. Storage nodes perform search, and digest nodes perform search on the most current segments as well as live searches. Digest nodes do the work of digesting data read from Kafka, and storing it in segment files. Often it makes sense to have nodes doing both storage and digest. Then the digest/storage node's resources can be utilized for both searching and digesting. If a spike occurs in ingest then all of the digest/storage machine's cores can be used to handle the spike in digest data without delays. On the other hand, if fewer resources are being used digesting, then all remaining cores can be used for faster searching. LogScale prioritizes digest work over search.
Separating digest and storage workloads can be good for isolating problems. Resource-intensive historical searches would not run on digest nodes and take up resources that should be used for digest work. Digest nodes also uses less disk space than storage nodes. As digest nodes hold the most recent data their disks should provide the highest performance possible.
Separate frontend (HTTP) nodes
LogScale supports the following three frontend roles: ingest, query coordination and UI/API. The following discusses the tradeoffs in separating the roles on different machines:
Ingest - Ingestion requests are by far the biggest source of incoming traffic, both in terms of request rates and request sizes. The requests can also vary a lot. Some clients will send small request with little batching while others will send larger requests. Some clients will open many connections, while others will be better at reusing and multiplexing requests. Most logshippers are mature and tested thoroughly. They will perform correctly (when suitably configured for the use case) but there is no guarantee, as failure scenarios and edge cases can occur. Creating a robust client for shipping logs is not an easy task. That is why CrowdStrike always recommends existing products if possible(for example the LogScale Collector). Do not write your own. CrowdStrike Support has experienced many scripts/programs shipping logs that worked well initially, but did not handle all failure scenarios well, or did not handle ingest spikes. Some of the typical problems with less mature clients include:
Clients that do not back off when receiving error codes. Instead, they start opening more connections and sending more requests.
Clients sending one event in each request. Then when suddenly there is a spike in events they send a burst of requests.
Ingest data is also parsed in LogScale. Typically a parser has been written that parses the incoming data. A parser is written using the LogScale query language which provides flexibility, but has the potential to result in resource-heavy queries. For example, it is possible to write arbitrary regular expressions (LogScale puts some boundaries on what is possible and will measure how much work is spent in a regular expression and potentially terminate the query). Therefore, it is possible for the parser to consume a large amount of resources for some queries. Parsers may work well when initially created, but may later cause problems. For example, the parser works smoothly for the events up until the input changes and is much more expensive to parse. Or it's initially acceptable that the parser is slow, as long as not many events are being received, but parsing fails when the ingest volumes spike.
LogScale will measure how much time is spent ingesting/parsing and can throttle/block ingest if necessary. The load balancer in front of LogScale also plays an important role in connection handling and request rate/size limiting.
For these reasons in can be difficult to manage ingest. It can therefore be useful to be able to isolate ingestion and not have it potentially impact other parts of the system. For example, a faulty log shipping client can open too many connections. In this case you still want to be able to access the cluster on your non-ingest endpoints to fix the problem.
Query Coordination - Query coordination has higher memory requirements than the other frontend roles. Isolating query coordination from other workloads can therefore be beneficial.
UI/API nodes - The number of requests and the workload for these nodes is typically much smaller than for the other frontend roles. This work can often be done on relatively low specification machines. Multiple machines are typically only needed for fault tolerance. It can still be beneficial to have separate nodes for this role, so it is always possible to access the cluster even if the other frontend nodes are having problems. Sometimes it can even make sense to have a node that is only accessible by administrators of the cluster, so they can manage the cluster effectively if issues arise.