
Digest Rules
Digest Node are responsible for executing real-time queries and compiling incoming events into segment files.
Whenever parsing is completed, new events are placed in a Kafka queue called humio-ingest.
Partition Assignment to Nodes
The exact placement of segment data and assignment of digest work to nodes is automated. Segments should be thought of as divided into two groups: Newly written segments, and older segments. Digest settings dictate placement of newly written segments, while storage settings dictate placement of older segments. We provide the following settings, which influence the placement in various ways:
The replication factor for digest/storage — This setting is configured via the UI, or the setDigestReplicationFactor or setSegmentReplicationFactor GraphQL mutations. The automation will use this factor to decide how many copies of each segment to store.
The
ZONEenvironment variable — This setting defines the zone of a node. The automation will account for zones, by attempting to distribute segments and digest partitions to as many zones as possible, while respecting the replication factor.The
CPUcores on the host — This is not configurable, but the automation of digest work placement accounts for CPU cores, and will attempt to assign digest partitions evenly, such that each digest partition gets roughly an even number of cores. This balancing is lower priority than respecting zoning, so if it is not possible to optimize both, good distribution across zones is preferred.The disk size on the host — This is not configurable, but the automation of segment placement for older segments will attempt to even out disk usage for cluster nodes, by placing segments on hosts that use a lower percentage of their disk space.
The
NODE_ROLESenvironment variable — This setting defines which work a node is able to perform. Nodes can be assigned roles meaning they cannot be assigned digest work, or segments, which the automation will respect.The
PRIMARY_STORAGE_MAX_FILL_PERCENTAGEenvironment variable (SECONDARY_STORAGE_MAX_FILL_PERCENTAGEon nodes that have secondary storage configured). — This setting defines the maximum amount of disk to use for segment storage. The automation will attempt to place more segments on nodes farther from the disk limit. Segment placement uses the secondary version of this setting if secondary storage is configured, otherwise the primary version is used. The automation will also attempt to move segments between hosts to balance disk usage, if disks are very unevenly filled in the cluster. This balancing is lower priority than respecting zoning, so if it is not possible to optimize both, good distribution across zones is preferred. If a host hits the disk limit, it will enter an error state, where it will attempt to avoid writing more bytes to its local disk until space can be freed.
Important
When scaling CPUs for digest nodes, it is important to scale the storage by a proportionate amount. For example, if you double the number of CPUs on a digest node, you should double the storage. This is because a greater number of CPUs causes a corresponding increase in the segments created and stored on disk. If the number of CPUs in a digest node was increased without a corresponding increase in storage allocation, then the node would have many more segment files than other digest nodes, causing a skewed distribution of segments.
On clusters with bucket storage configured, the replication factor for older segments may be ignored for segments that are already present in bucket storage. This will happen if the cluster is retaining more data than can fit on the local disks. In this case, the cluster may delete copies of segments from the local disks if those segments are also present in the bucket, in order to avoid filling the disks completely. The relevant settings to control this behavior are:
The
LOCAL_STORAGE_PERCENTAGEenvironment variable — When a node exceeds using this percentage of the primary (or secondary if present) disk, older segments may be deleted from the local disk if they are also present in bucket storage.The
LOCAL_STORAGE_PREFILL_PERCENTAGEenvironment variable — The percentage of the local primary (or secondary if present) disk to prefetch data from bucket storage for. Normally segments are only fetched from bucket storage on demand as queries need them. When adding new empty nodes to the cluster, prefetching can allow them to fetch data to local disks without waiting for queries to need them.
Digest Partitions
A cluster will divide data into partitions (or buckets); we cannot know
exactly which partition a given event will be put in. Partitions are
chosen randomly to spread the workload evenly across digest nodes. These
partitions should correlate with the number of Kafka
humio-ingest topic partitions,
which uses a default of 24.
Each partition of that queue must have a node associated to handle the work that is placed in the partition, or they will not be processed or saved.
LogScale clusters have a set of rules that associate partitions in the Digest Queue with the nodes that are responsible for processing events on that queue. These are called Digest Rules.
Digest Partition Rules are managed automatically.
Viewing Digest Rules
Available: Automatic Configuration v1.80.0
As of v1.80.0, these digest rules are automatically configured.
Digest rules are automatically configured.
To see the current digest rules for your own cluster:
Go to your profile account menu on the top right of the user interface and select
In the
System Administrationpage → Cluster nodes tab, click : the rules are shown in the panel on the right-hand side.
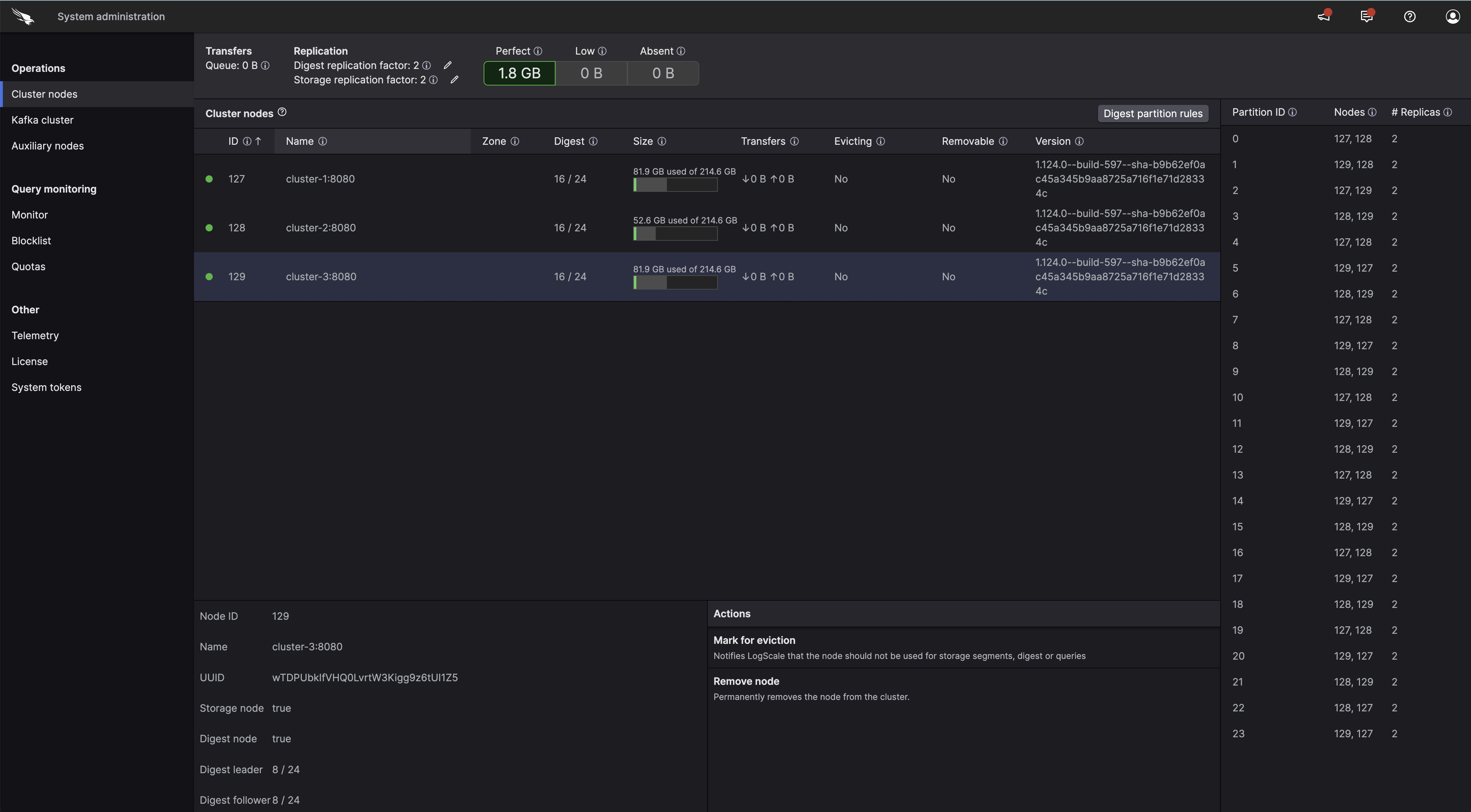 |
Figure 87. Configuring Digest Rules
The image above shows digest rules for a cluster of three nodes where each node is assigned to 16 out of 24 digest partitions.
When a node is assigned to at least one digest partition, it is considered to be a Digest Node.
The table shows three digest rules. Node
1 will receive 2x more work than
node 3. This is because
1 is assigned to two partitions
while node 3 is only handling
events on partition 2.
If a node is not assigned to a partition, it will not take part in the digest phase.
Increasing Digest Partitions
Important
This operation is not reversible. Once you've increased partitions, you cannot later decrease the number you're using.
If additional digest nodes are added to a cluster, you will likely want to increase the number of digest partitions to ensure all digest nodes are able to consume from at least one partition. To do this, you must first increase the number of partitions for the Kafka humio-ingest topic. Increasing the number of Kafka partitions for a topic involves logging into one of your Kafka nodes and running this command:
/usr/lib/kafka/bin/kafka-topics.sh --alter --zookeeper \
localhost:2181 --topic humio-ingest --partitions 28
The path to kafka-topics.sh may vary depending on
installation type. Docker containers may have this at
/products/kafka/bin.
Ansible-based installs will have it at the above path. If you installed
this by hand, use the path where Kafka is installed.
Up to LogScale 1.107: if ZooKeeper is running on the Kafka machine, use
localhost for the ZooKeeper address; otherwise specify its actual
hostname or IP. Replace 28 with whatever
total partition count you're after (note that you're specifying the
total and not the number of partitions being added). After running the
command, you should see output that says "Adding partitions succeeded!".
LogScale will configure itself based on the number of partitions in Kafka.
$ curl -v -H "Content-Type: application/json" \
-H "Authorization: Bearer APITOKEN" \
http://127.0.0.1:8080/api/v1/clusterconfig/ingestpartitions[
{
"hosts": [1],
"partition": 0
},
{
"hosts": [1],
"partition": 1
},
{
"hosts": [1],
"partition": 2
},
{
"hosts": [1],
"partition": 3
},
{
"hosts": [1],
"partition": 4
},
{
"hosts": [1],
"partition": 5
},
{
"hosts": [1],
"partition": 6
},
{
"hosts": [1],
"partition": 7
},
{
"hosts": [1],
"partition": 8
},
{
"hosts": [1],
"partition": 9
},
{
"hosts": [1],
"partition": 10
},
{
"hosts": [1],
"partition": 11
},
{
"hosts": [1],
"partition": 12
},
{
"hosts": [1],
"partition": 13
},
{
"hosts": [1],
"partition": 14
},
{
"hosts": [1],
"partition": 15
},
{
"hosts": [1],
"partition": 16
},
{
"hosts": [1],
"partition": 17
},
{
"hosts": [1],
"partition": 18
},
{
"hosts": [1],
"partition": 19
},
{
"hosts": [1],
"partition": 20
},
{
"hosts": [1],
"partition": 21
},
{
"hosts": [1],
"partition": 22
},
{
"hosts": [1],
"partition": 23
}
]
You can check the digest partitions in LogScale from the
System Administration page →
Cluster nodes → Digest.
High Availability
LogScale has High Availability support for digest nodes.
The HA option works as follows.
Run a cluster of at least 2 nodes.
Set the digest and storage replication factor to
2, you can do so by clicking the pencil icons found under Replication: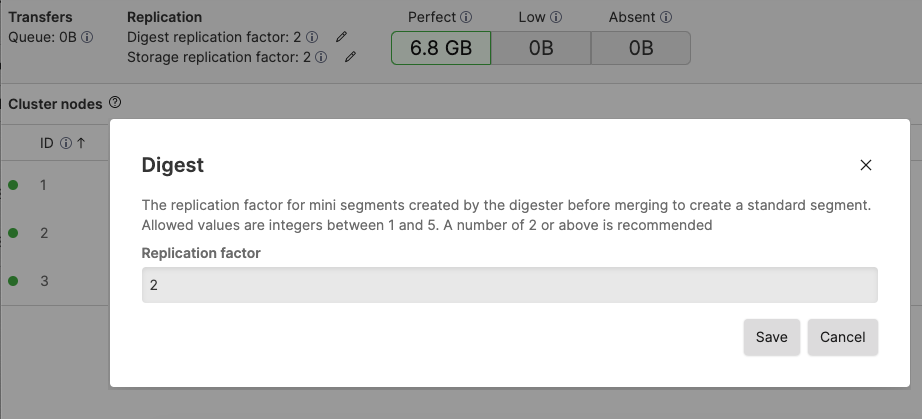
Figure 88. Setting Replication Factors
If any data is present on only one node, then queries will get warnings saying Segment files missing, partial results.
Make your http-load-balancer know about more than one node in the cluster; preferably all of them.
Make sure your cluster has the CPU power required to handle the failover: It should be running at well below 50% utilization normally.
This feature presumes that your Kafka cluster is properly configured for high-availability — all topics in use by LogScale need to have at least two replicas on independent server nodes.
High Availability in LogScale
The design aims for high performance during normal operation at the cost of a penalty to be paid when a failover situation happens.
Turn on high availability on ingest by configuring all digest partitions to have two or more nodes listed. The first live node in the list will handle that partition during normal operation. If the primary node stops, then the next one in the list will take on the responsibility of handling the digest on that partition. If the primary returns at some point, then the primary will resume responsibility for that partition. This happens independently for all digest partitions.
To get proper results in all live queries, all live queries get restarted when a node stops.
The node that then takes on the digest processing has to start quite a way back in time on the digest queue, processing all events (again probably) that have not yet been written to segments replicated sufficiently to other nodes. LogScale takes care to ensure that events only get included once in a query, regardless of the re-processing in digest, including not duplicating them once the failed node returns and has those events as well.
The failover process can take quite while to complete, depending on how much data has been ingested during the latest 30 minutes or so. The cluster typically needs to start 30 minutes back in time on a failover. While it does so, the event latency of events coming in will be higher than normal on the partitions that have been temporarily reassigned, starting at up to 1800 - 2000 seconds. The cluster thus needs to have sufficiently ample CPU resources to catch up from such a latency fairly quickly. To aid in that process, queries get limited to 50% of their normal CPU time while the digest latency is high.
Fail-over makes the cluster start much further back in time compared to a controlled handover between two live nodes. When reassigning partitions with the nodes active, the nodes cooperate to reduce the number of events being reprocessed to a minimum, making the latency in ingested events typically stay below 10 seconds.
The decision to go with the 30 minutes as target failover cost is a compromise between two conflicting concerns. If the value is raised further, the failover will take even longer, which is usually not desirable. But raising it reduces the number of small segments generated, since segments get flushed after at most that amount of time. Reducing the 30-minute interval to say, five minutes would make the failover happen much faster, but at the cost of normal operation, as there would be 12 * 24 = 288 segments in each datasource per day, compared to the 2 * 24 = 48 with the current value. The cost of having all these extra segments would slow down normal operation somewhat.
There are a number of configuration parameters to control the trade-offs. Here they are listed with their defaults.
# How long can a mini-segment stay open. How long back is a fail-over likely to go?
FLUSH_BLOCK_SECONDS=1800
# Desired number of blocks (each ~1MB before compression) in a final segment after merge
BLOCKS_PER_SEGMENT=2000
# How long cn the same segment be the final target of all the minisegments being produced?
MAX_HOURS_SEGMENT_OPEN=24