

Amazon Bucket Storage
LogScale supports writing a copy of the ingested logs to Amazon S3 using the native file format of LogScale, allowing LogScale to fetch those files and search them efficiently if the local copies are lost or deleted. For more details on this topic in general, see the Bucket Storage page.
If you use S3 for bucket storage, two options for encryption are supported (you can apply both):
LogScale-implemented and enforced, not relying on any support from the bucket provider. It is controlled by the configuration variable
S3_STORAGE_ENCRYPTION_KEY, which is applied whenever its value is not set tooff(because this value would disable the use of an encryption key).AWS-implemented. Access to objects and decryption is managed by AWS as the object storage provider. To ensure better security using AWS supplied encryption, you may want to turn on KMS key for encrypting objects in S3 via the
S3_STORAGE_KMS_KEY_ARNconfiguration — for more information on how Key Management Service works on the AWS side, see Amazon S3 documentation.
Configure an Amazon S3 Bucket
LogScale supports multiple ways of configuring access to the bucket, allowing you to use any of the 5 listed in Using the Default Credential Provider Chain on top of the following, which takes precedence if set.
If you run your LogScale installation outside AWS, you need an
IAM user with write
access to the buckets used for storage. That user must have
programmatic access to S3, so when adding a new user through the AWS
console make sure programmatic
access is set.
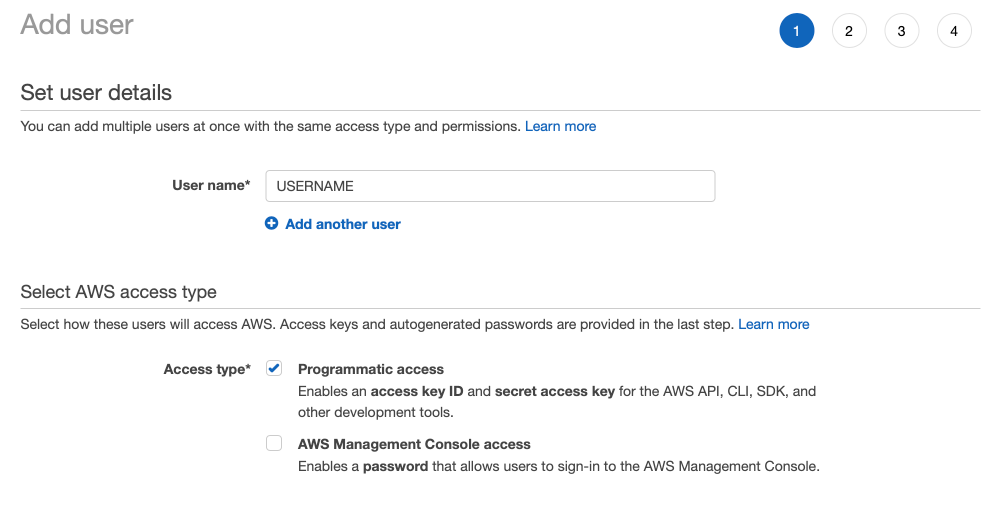 |
Figure 64. Self-Hosting with S3
Later in the process, you can retrieve the access key and secret key:
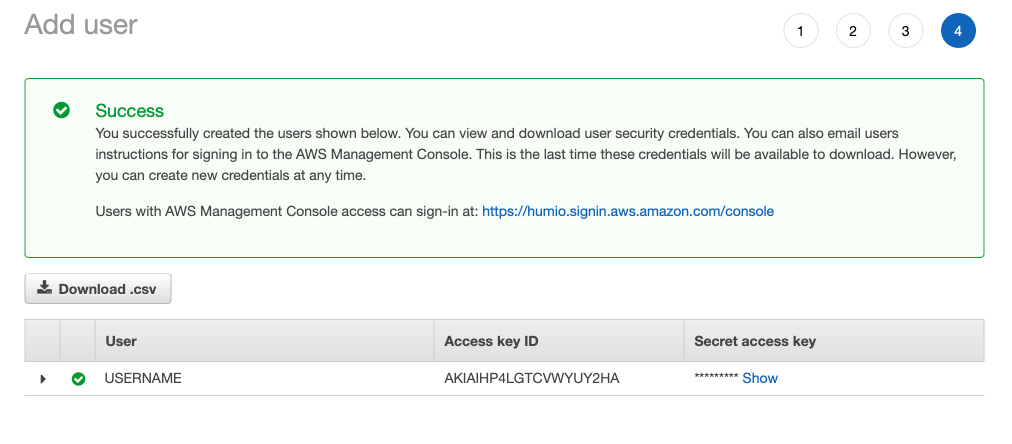 |
Figure 65. Self-Hosting with S3
Enable S3 Storage in LogScale
To configure S3 storage, the access key and secret key from the S3
bucket configuration must be set using the corresponding
S3_STORAGE_ACCESSKEY and
S3_STORAGE_SECRETKEY configuration variables.
Note
See Encryption of S3 Bucket Data for more information on the LogScale encryption key used for storing bucket data. In the example below, use of a LogScale encryption key has been disabled.
For example:
# These two take precedence over all other AWS access methods.
S3_STORAGE_ACCESSKEY=$ACCESS_KEY
S3_STORAGE_SECRETKEY=$SECRET_KEY
S3_STORAGE_ENCRYPTION_KEY=offAlternative variables are also supported:
# Also supported:
AWS_ACCESS_KEY_ID=$ACCESS_KEY
AWS_SECRET_ACCESS_KEY=$SECRET_KEYThe keys are used for authenticating the user against the S3 service. For more guidance on how to retrieve S3 access keys, see AWS access keys. More details on creating a new user in IAM.
Configuring the user to have write access to a bucket can be done by attaching the right access policy to the user.
Encryption of S3 Bucket Data
Amazon S3 enforces server-side encryption of stored data since January 2023. Explicit configuration of an encryption key for storage of bucket data must be configured. Without explicit declaration of an encryption key, S3 bucket key encryption in LogScale is required due to the checksum reported by S3 being different to the checksum calculated by LogScale.
Best practice is to use the key managed by Amazon Service Side Encryption (SSE) with KMS support turned on, in place of the key configured and stored on disk in plain text.
KMS support in LogScale is controlled via the
S3_STORAGE_KMS_KEY_ARN configuration.
To switch off additional LogScale encryption in LogScale:
S3_STORAGE_ENCRYPTION_KEY=offThis will allow data stored in S3 to be encrypted using the the Amazon S3 configured key (see Protecting data with server-side encryption for more information).
Using a custom key is supported, and can be configured to encrypt the bucket data by setting the encryption key explicitly:
S3_STORAGE_ENCRYPTION_KEY=customencryptionkeyThis key will be used in addition to the SSE key used.
When using this option, LogScale automatically disables
checking of the encryption tag information once AWS Key Management
Service is configured (through the
S3_STORAGE_KMS_KEY_ARN environment variable).
IAM User Example Policy
The following JSON is an example policy configuration:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::BUCKET_NAME"]
},
{
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:GetObject", "s3:DeleteObject"],
"Resource": ["arn:aws:s3:::BUCKET_NAME/*"]
}
]
}The policy can be used as an inline policy attached directly to the user through the AWS console:
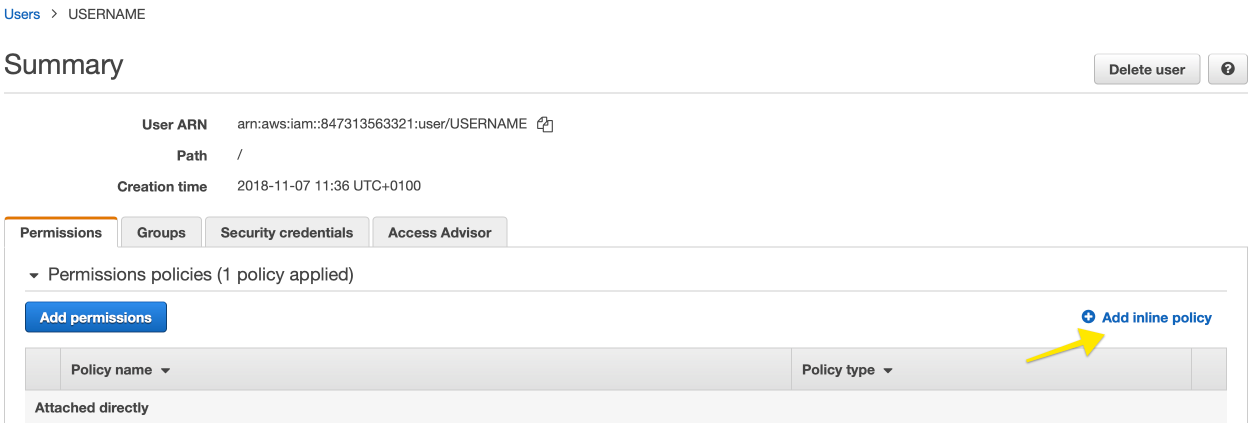 |
Figure 66. IAM User Example Policy
You must also tell which bucket to use. These settings must be identical on all nodes across the entire cluster.
S3_STORAGE_BUCKET=$BUCKET_NAME
S3_STORAGE_REGION=$BUCKET_REGION
S3_STORAGE_ENCRYPTION_KEY=$ENCRYPTION_SECRET
S3_STORAGE_OBJECT_KEY_PREFIX=/basefolder
USING_EPHEMERAL_DISKS=true
The first option here is to set the name of the bucket to use. The
encryption key given with S3_STORAGE_ENCRYPTION_KEY can
be any UTF-8 string. The suggested value is 64 or more random ASCII
characters.
The S3_STORAGE_OBJECT_KEY_PREFIX is used to set the
optional prefix for all object keys allows multiple LogScale
clusters to use the same bucket. The prefix is unset by default.
Note
There is a performance penalty when using a non-empty prefix. We
recommend an unset prefix. If there are any ephemeral disks in the
cluster, you must set the last option here to
true.
Switch to a Fresh Bucket
You can change the settings using the
S3_STORAGE_BUCKET and
S3_STORAGE_REGION to point to a fresh bucket at any
point in time. From that point, LogScale will write new
files to that bucket while still reading from any
previously-configured buckets. Existing files already written to any
previous bucket will not get written to the new bucket.
LogScale will continue to delete files from the old buckets
that match the file names that LogScale would put there.