
Create a Parser
A parser consists of a script and parser settings like Event Tags and Fields to Remove. The parser script, written in the LogScale Query Language, defines how a single incoming event is transformed before it becomes one (or more) searchable event. LogScale has built-in parsers for common log formats like accesslog.
The goal for a parser script is to:
Extract the correct timestamp from the event
Set the fields you want to use frequently in your searches
The following diagram provides an overview of where parsers fit in the configuration flow to ingest data using LogScale.
Figure 45. Flow
The main text of the ingested event is present in the field @rawstring, and many functions used for parsing will default to using @rawstring if no field is specified, so a parser may easily parse the incoming data without ever referring explicitly to @rawstring in the script.
Other fields may also be present though, depending on how logs are sent to
LogScale. For example, Falcon LogScale Collector will add a
few fields such as @collect.timestamp
which are present and usable in the parser. In other words, an input event
for a parser is really a collection of key-value pairs. The main key is
@rawstring, but others can be present from the
beginning as well, and the parser can use those as it would do with any
other fields.
The contents of @rawstring can also be any kind of text value. It's common to see e.g. JSON objects or single log lines;@rawstring doesn't require any specific format, and you can send whatever data you like.
Setting the correct timestamp is important, as LogScale relies on this field to find the right results when you search in a given time interval. You do this by assigning the timestamp to the @timestamp field, formatted as a UNIX timestamp. Functions such as parseTimestamp() are designed to make this easy. See https://library.humio.com/data-analysis/parsers-parsing-timestamps.html.
Setting fields you want to search for in the parser is optional, though highly recommended. That's because fields can also be extracted at search time, so the parser does not need to meticulously set every field you might want to use. However, searching on fields which have been set by the parser is generally easier, in terms of writing queries, and also performs better, in terms of search speed.
If you have checked the list of preconfigured parsers and found that nothing quite matches what you need, then this guide will show you how to create your own (or edit an existing one) parser.
Create a New Parser
Security Requirements and Controls
Change parserspermission
This section describes how to create a parser from scratch.
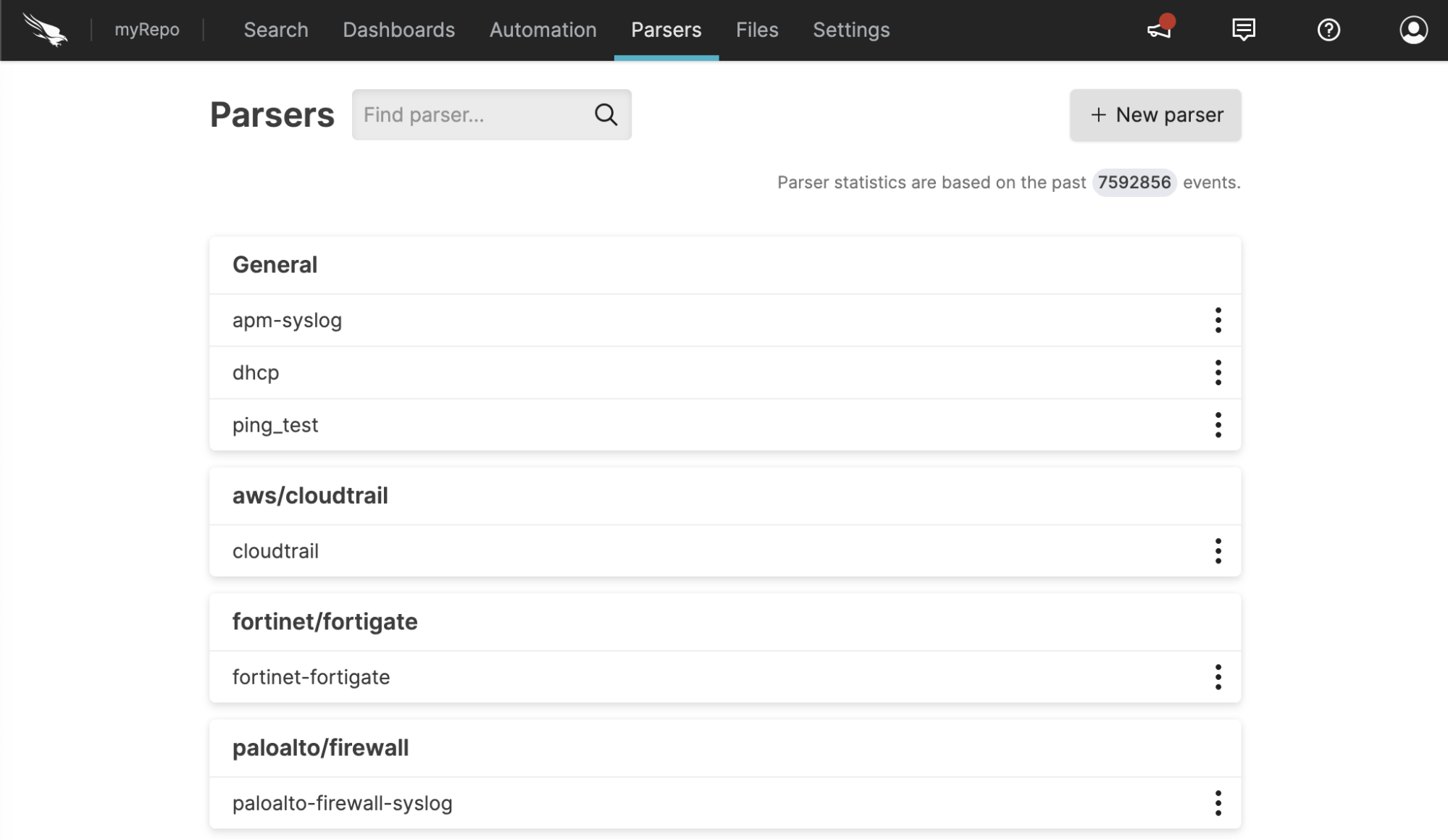 |
Figure 46. Parser Overview
Go to
Repositories and Viewspage and select the repository where you want to create a parser.Click to reach the parser overview, and then click , see Figure 46, “Parser Overview”.
In the New parser dialog box, enter a name for the parser: only alphanumeric characters, underscore and hyphen are allowed, and the name must be unique inside the repository.
Select how to create the parser:
Empty Parser – Select Empty parser and click .
Clone Existing – Select Duplicate existing, select a parser from the Duplicate Template list and click .
From Template – Select From template, browse for or drag and drop a parser and click .
From Package – Select From package and click .
Clicking will open a code editor where you can write a script for the parser.
Write a Parser
Once you have created your parser, you will be presented with an editor.
 |
Figure 47. Parser Editor
On the left side is the script, and on the right are the test cases you can run the script on. You can click on a test case after running tests to see the event it produced.
Writing a good parser starts by knowing what your logs look like. So it is best to gather some sample log events. Such samples may be taken from log files for example, or if you are already ingesting some data, you may be able to use the contents of the @rawstring fields.
As @rawstring can be changed during parsing, and different methods of sending logs may imply different data formats, you should verify that your samples are representative, as soon as you start sending real data.
Then, write your parser script. Note that the main difference between
writing a parser and writing a search query is that you cannot use
aggregate functions like groupBy().
Write Test Cases
Add samples as tests for your parser, where each test case represents an ingested event, with the contents of the test case being available in the @rawstring field during parsing.
Click and write test case logic in the textbox.
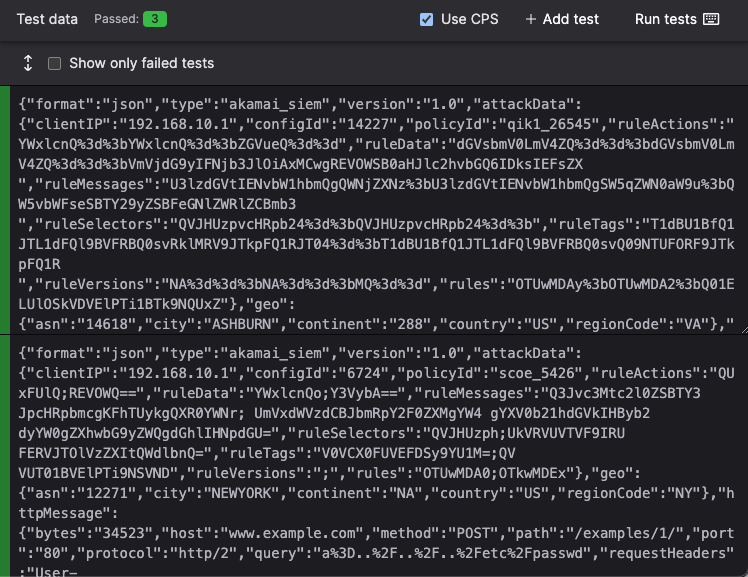
Figure 48. Test Case for a Parser
Once you have added some tests to your parser, click the button to see the output that your parser produced for each of them. See Figure 49, “Test Case Output after Parsing” for an example.
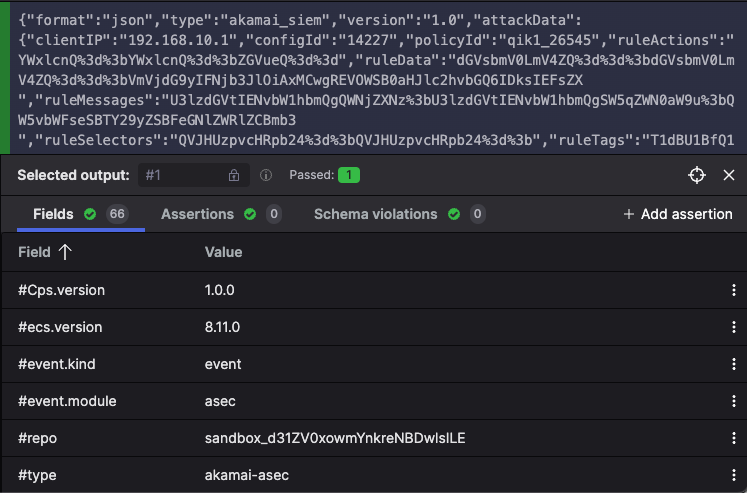
Figure 49. Test Case Output after Parsing
Errors, Validation Checks, and Warnings
When writing a parser, the test case output might show some validation messages, or return failed tests whenever errors or warnings occur. All these are output in different situations and produce a different behavior in the parser:
Errors. The parser fails to parse incoming data, and LogScale adds @error fields to the event. See Parser Errors for more details.
Validation checks. The parser does not fail: these are messages intended as guidelines on how you should write your parser. For example, arrays must be contiguous and have a
0thindex. Fields that are prefixed with#must be configured to be tagged (to avoid falsely tagged fields). See Parsers Validation Errors for more details.Optionally, you can also validate if your parser normalizes test data, as described in Normalize and Validate Against CPS Schema. Fixing parser validation errors is recommended before deploying your parser, but it does not prevent you from saving your parser script.
Warnings. The parser does not fail and continue parsing the event, but the test case shows a warning.
Assertions
In addition to seeing the concrete output the parser produced, you can also add Assertions on the output. This means that you can specify that you expect certain fields to contain certain values, and the tests will fail if that does not hold.
This is especially useful if you need to apply regular expressions, as they can be tricky to get right the first time, but also tricky to change over time without introducing errors. See Figure 52, “Assertions” for an example.
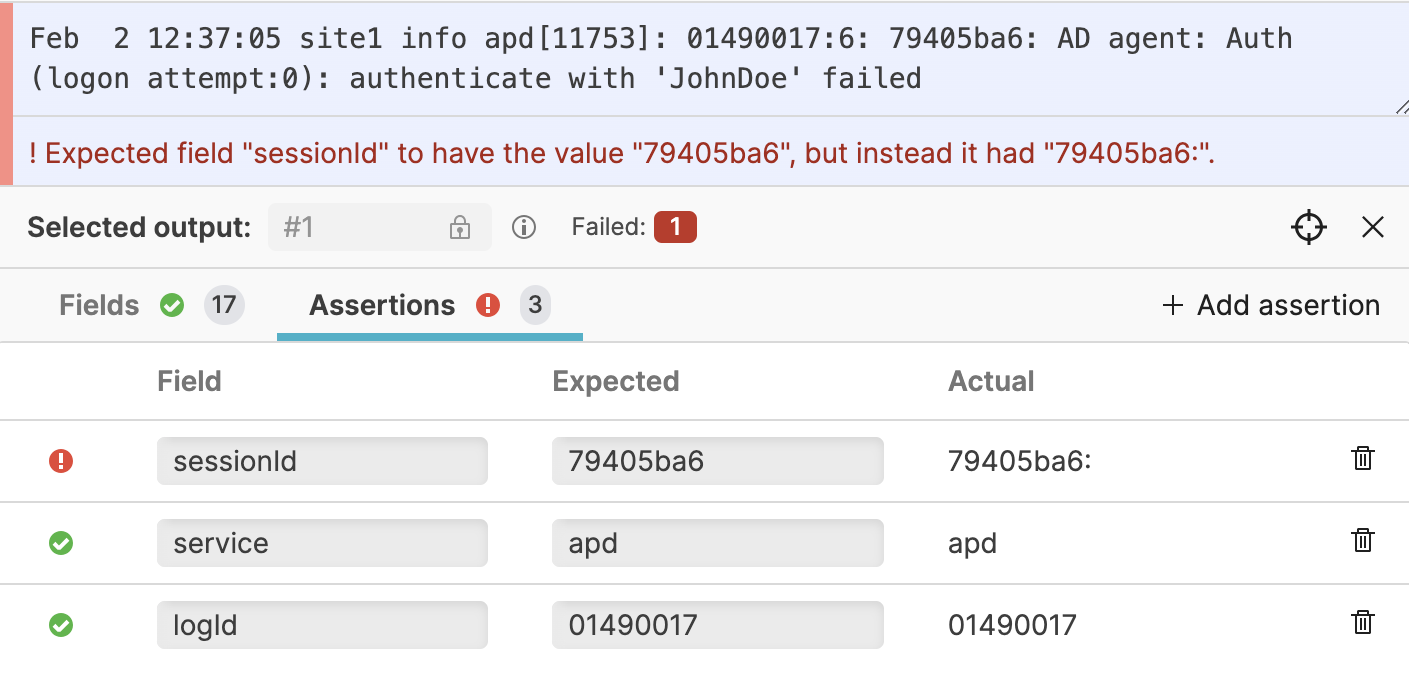 |
Figure 52. Assertions
Example: Parsing Log Lines
Assume we have a system producing logs like the following two lines:
2018-10-15T12:51:40+00:00 [INFO] This is an example log entry. server_id=123 fruit=banana
2018-10-15T12:52:42+01:30 [ERROR] Here is an error log entry. class=c.o.StringUtil fruit=pineappleWe want the parser to produce two events (one per line) and use the timestamp of each line as the time at which the event occurred; that is, assign it to the field @timestamp, and then extract the "fields" which exist in the logs to actual LogScale fields.
To do this, we will write a parser, and we'll start by setting the correct timestamp. To extract the timestamp, we need to write a regular expression like the following:
@rawstring = /^(?<temp_timestamp>\S+)/
| parseTimestamp("yyyy-MM-dd'T'HH:mm:ss[.SSS]XXX", field=temp_timestamp)
| drop(temp_timestamp)This creates a field named temp_timestamp using a "named group" in the regular expression, which contains every character from the original event up until the first space, i.e. the original timestamp. The regular expression reads from the @rawstring field, but it doesn't modify it; it only copies information out.
With the timestamp extracted into a field of its own, we can call parseTimestamp() on it, specifying the format of the original timestamp, and it will convert that to a UNIX timestamp and assign it to @timestamp for us. With @timestamp now set up, we can drop temp_timestamp again, as we have no further need for it.
In addition to the timestamp, the logs contain more information. Looking at the message
2018-10-15T12:51:40+00:00 [INFO] This is an example log entry. server_id=123 fruit=bananaWe can see:
The log level
INFOThe message
This is an example log entryThe server_id
123The fruit
banana
To extract all of this, we can expand our regular expression to something like:
/^(?<temp_timestamp>\S+) \[(?<logLevel>\w+)\] (?<message>.*?)\. (?<temp_kvPairs>.*)/
The events will now have additional fields called logLevel (with value
INFO) and message (with value
This is an example log entry), which we
can use as is. The event also has a
temp_kvPairs field, containing
the additional fields which are present after the message i.e.
id=123 fruit=banana. So we still need to
extract more fields from
temp_kvPairs, and we can use the
kvParse() function for that, and drop
temp_kvPairs once we are
finished.
As a result, our final parser will look like this:
@rawstring = /^(?<temp_timestamp>\S+) \[(?<logLevel>\w+)\] (?<message>.*?)\. (?<temp_kvPairs>.*)/
| parseTimestamp("yyyy-MM-dd'T'HH:mm:ss[.SSS]XXX", field=temp_timestamp)
| drop(temp_timestamp)
| kvParse(temp_kvPairs)
| drop(temp_kvPairs)Example: Parsing JSON
We've seen how to create a parser for unstructured log lines. Now let's create a parser for JSON logs based on the following example input:
{
"ts": 1539602562000,
"message": "An error occurred.",
"host": "webserver-1"
}
{
"ts": 1539602572100,
"message": "User logged in.",
"username": "sleepy",
"host": "webserver-1"
}Each object is a separate event and will be parsed separately, as with unstructured logs.
The JSON is accessible as a string in the field
@rawstring. We can extract fields from the JSON by
using the parseJson() function. It takes a field
containing a JSON string (in this case @rawstring)
and extracts fields automatically, like this:
parseJson(field=@rawstring)
| @timestamp := ts
This will result in events with a field for each property in the input
JSON, like username and
host, and will use the value of
ts as the timestamp. As
ts already has a timestamp in
the UNIX format, we don't need to call
parseTimestamp() on it.
Next Steps
Once you have your parser script created you can start using it by Ingest Tokens.
You can also learn about how parsers can help speed up queries by Parsing Event Tags.
Parsers Validation Errors
The errors listed here do not represent ingest errors. These errors are related to the content of your parser, serving as guidelines as to how you should write your parser, to make sure that it is consistent and functions works as intended. The errors you encounter here will (in many cases, some exceptions if it is a parser error) not be visible on events that are actually ingested.
Static Output validation
These validations are run against all test cases and cannot be disabled. Their purpose is to make sure that queries against your event will work.
| Message | Description | Solution |
| myFieldName is not searchable. When searching for this field, LogScale will not find this event, because fields starting with # are searched as tags." | The field has been falsely tagged. The symbol # has manually been prefixed to the field's name, however, this does not create a tagged field, but instead a field with that name. This affects searching as queries will search for a tagged field, which cannot be found, as no such tag exists. | Remove the # prefix from your field changing it from #myFieldName to myFieldName. Then go into Parser > Settings> Fields to Tag and add myField to the list if you intend to tag the field. The parser script will now produce a field named #myFieldName and remove myFieldName from the event |
| The array myArrayName has gaps, which affects searching with array functions. There are elements missing at indexes: indexnumber, and larger gaps between: gap |
There are missing indices and larger gaps in the array. Arrays must be without any gaps and start at index 0 for array functions to work correctly. For more information see, array syntax at Array Syntax. |
Remove the gaps in your array. The recommended approach is
to use the array:append() function to
construct arrays. This ensures that there are no gaps in the
output.
|
| The array myArrayName has gaps, which affects searching with array functions. There are gaps between these indexes: indexnumber. |
There are gaps in the array. Arrays must be without any gaps and start at index 0 for array functions to work correctly. For more information see, array syntax at Array Syntax. |
Remove the gaps in your array. The recommended approach is
to use the array:append() function to
construct arrays. This ensures that there are no gaps in the
output.
|
The array
myArrayName has
gaps, which affects searching with array functions. There
are elements missing at indexes:
indexnumber.
|
There are some indices missing in the array. Arrays must be without any gaps and start at index 0 for array functions to work correctly. For more information see, array syntax at Array Syntax. |
Remove the gaps in your array. The recommended approach is
to use the array:append() function to
construct arrays. This ensures that there are no gaps in the
output.
|