

Use Case: A Better Parser with Kubernetes & LogScale
You need an self-hosted installation of LogScale. The parser must be
configured with repo as a tagging
field. It requires the configuration option
ALLOW_CHANGE_REPO_ON_EVENTS be set to
true, which is why this is not
supported by Hosted LogScale.
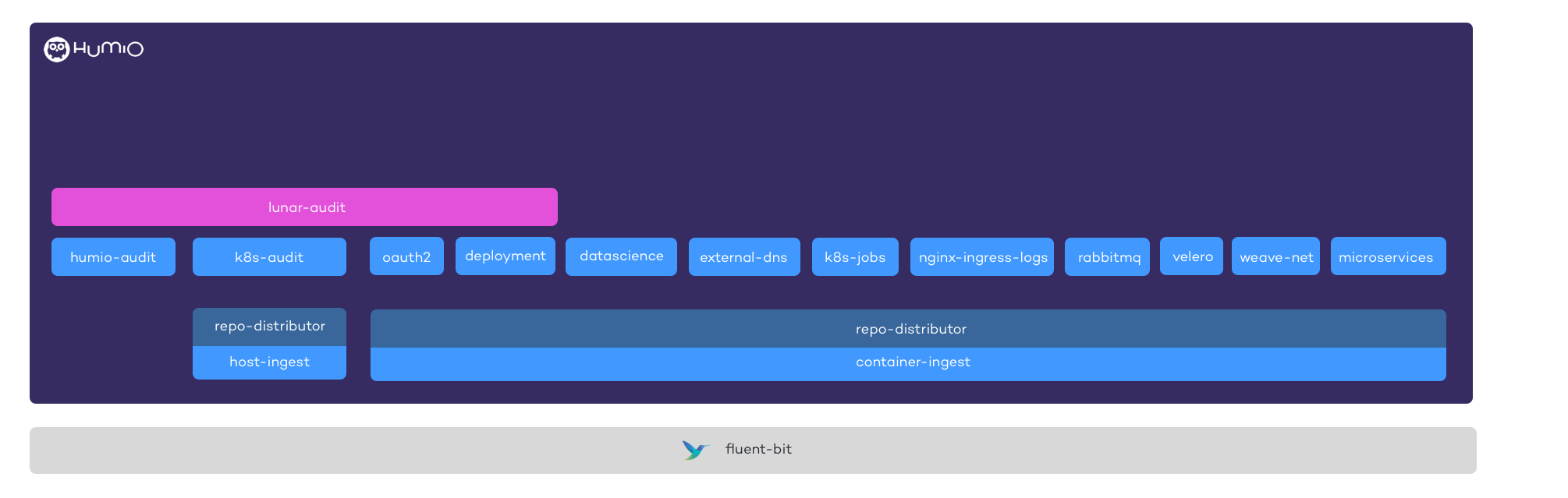 |
Figure 16. Lunarway
We're basically just ingesting everything from
hg b/var/log/containers/*.log to
the container-ingest repo, where I have
set up a parser named
repo-distributor . Now you
can use the parser to ship logs to different repos and do the parsing
here. This is so much easier than what we did before, with editing
Fluentd configuration files, redeploying these every time we changed the
logs, creating multiple repos with ingest tokens, and adding them to
specific outputs in Fluentd. Now we just pick everything up, if there's
no match in the repo-distributor , logs
will stay in this repo, and we can now just forward them to a specific
repository without changing anything in the log shipper.
case {
// --------------------------
// CASE: Match type=services
// --------------------------
k8s.labels.type = "service"
|
parseJson(field=log)
|
// Handle timestamp for different services
case {
k8s.labels.app = "bec*"
| parseTimestamp(field=event_time);
k8s.labels.app = "api"
| parseTimestamp("yyyy-MM-dd HH:mm:ss.SSS", field=timestamp, timezone="UTC");
true
| parseTimestamp(field=@timestamp);
}
|
// Handle empty message
case {
message != *
| message := log;
true;
}
|
// Handle missing log level
case {
level != *
| level := "unhandled";
true;
}
|
format("[%s] %s", field=[k8s.labels.app,message], as="@rawstring")
|
repo := "microservices";
// --------------------------
// CASE: Datascience
// --------------------------
k8s.namespace_name = datascience
|
format("[%s] %s", field=[k8s.labels.app,log], as="@rawstring")
|
repo := "datascience";
// --------------------------
// CASE: NGINX Ingress Logs
// --------------------------
k8s.labels.app = "nginx-ingress-*"
|
regex("^(?<host>[^ ]*) - \[(?<real_ip>[^ ]*)\] - (?<user>[^ ]*) \[(?<time>[^\]]*)\] \"(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?\" (?<code>[^ ]*) (?<size>[^ ]*) \"(?<referer>[^\"]*)\" \"(?<agent>[^\"]*)\" (?<request_length>[^ ]*) (?<request_time>[^ ]*) \[(?<proxy_upstream_name>[^ ]*)\] (?<upstream_addr>[^ ]*) (?<upstream_response_length>[^ ]*) (?<upstream_response_time>[^ ]*) (?<upstream_status>[^ ]*) (?<last>[^$]*)", field=log)
|
format("[%s] %s %s %s", field=[code, method, proxy_upstream_name, path], as="@rawstring")
|
repo := "nginx-ingress-logs";
// --------------------------
// CASE: Kubernetes logs
// --------------------------
k8s.namespace_name = "kube-system" AND k8s.pod_name != weave-net*
|
format("[%s] %s", field=[k8s.pod_name,log], as="@rawstring")
|
repo := "kubernetes-temp";
// --------------------------
// CASE: Weave-net logs
// --------------------------
k8s.namespace_name = "kube-system" AND k8s.pod_name = weave-net*
|
format("[%s/%s] %s", field=[k8s.host,k8s.pod_name,log], as="@rawstring")
|
repo := "weave-net";
// --------------------------
// CASE: OAuth2
// --------------------------
"flb-key" = *oauth2*
|
regex("^(?<host>.*) - (?<user>[^ ]*) \[(?<ts>.*)\] (?<url>[^ ]*) (?<method>[^ ]*) (?<upstream>[^ ]*) \"(?<path>[^ ]*)\" (?<protocol>[^ ]*) \"(?<browser>.*)\" (?<status_code>[^ ]*)", field=log)
|
format("[%s/%s] [%s] %s %s %s ", field=[k8s.labels.app,user,status_code,method, url, path], as="@rawstring")
|
repo := "oauth2";
// --------------------------
// CASE: RabbitMQ
// --------------------------
k8s.labels.app = "rabbitmq"
|
parseJson()
| regex(regex="(?<ts>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3}) \[(?<level>\w+)\] <(?<erlang_process_id>\d+\.\d+\.\d+)> (?<message>.*)", field=log)
|
parseTimestamp("yyyy-MM-dd HH:mm:ss.SSS", field=ts, timezone="UTC")
|
format("[%s] %s ", field=[k8s.pod_name,message], as="@rawstring")
|
repo := "rabbitmq";
// --------------------------
// CASE: Match all other events
// --------------------------
true
| repo := "container-ingest";
}It's great to be able to look at the container-ingest repo, and just easily reformat and ship specific logs to specific repos based on function or retention requirements.
We are currently doing a lot of things in the repo-distributor parser, but I was thinking to add specific labels in Kubernetes either selecting a specific format (e.g. case in the parser) or maybe a specific format or regex to be used in the parser as an annotation in the Kubernetes deployment.
For more information, see the Kubernetes Log Format documentation.
This use case is a community submission from Kasper Nissen, Cloud Architect / Site Reliability Engineer @ LUNAR.