
Query Joins
LogScale supports the joining of queries using the
join() function. It will return a combined results
set from two queries it is given.
In order to the understand joins, consider that there is a list of events returned by a query in two separate lists of events; one on the right and one on the left. Joins return an intersection of those two event lists.
This function provides two join modes, inner and left:
Inner joins return a subset of events that match both sides of the query, i.e. only the events that have a corresponding match in each event list.
Left joins return everything in the list of the events on the left with any matching events corresponding events from the right.
An inner join will therefore return a reduced set of events, as it will be the intersection of lists of events. Left joins return all the matching from the left regardless of whether there is a match to an event on the right, and therefore return a longer list.
If you're familiar with SQL database systems, what would be the left table in SQL is referred to as the primary in LogScale, and the right table becomes the subquery.
Inner Joins
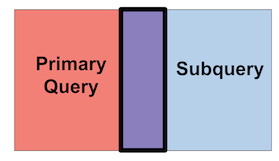 |
Figure 189. Inner Joins
An inner join returns any intersection of matching values (the purple
intersection in the example above), based upon the criteria you provide,
between the primary query and the subquery. This is illustrated in
purple in Figure 189, “Inner Joins” here. An inner
join is the join() function's default behavior.
As an example, suppose we're analyzing two repositories to see whether failed web page accesses and SSH connection failures are coming from the same IP address. In this example, we want to return the intersection of two types of data: the status codes that return errors (anything 400 or higher) from the weblog, and the SSH errors from the accesslog.
We can do this by matching events across two repositories and then comparing the two lists of event tables. Consider the following sample data from Apache access logs (in a repository called weblogs:
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/automated-alerts-manage.html HTTP/1.1" 200 249251
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/humio-cloud-identity-providers-saml.html HTTP/1.1" 200 244289
192.168.3.33 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/humio-cloud-identity-providers-configuration.html HTTP/1.1" 200 243435
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-scatter.html HTTP/1.1" 404 260601
192.168.1.49 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-sankey.html HTTP/1.1" 200 252146
192.168.1.76 - - [10/Mar/2023:11:16:32 +0000] "GET /ingesting-data/log-formats/kubernetes HTTP/1.1" 404 369And corresponding data that is tracking other forms of access, for example SSH in a repo called accesslog:
Mar 10 07:49:00 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:07 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:36 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:36 humiobase sshd[1850622]: Connection closed by invalid user user1 192.168.1.18 port 49361 [preauth]
Mar 10 07:51:16 humiobase sshd[1854832]: Accepted password for mc from 192.168.3.33 port 60928 ssh2
Mar 10 07:51:16 humiobase sshd[1854832]: pam_unix(sshd:session): session opened for user mc(uid=1000) by (uid=0)A multi-vector attack might be accessing non-existing web pages to fish for information, or trying to access a protected page without suitable authorization while also attempting to connect using ssh. Using a join, we can return entries from weblogs where an unsuccessful ssh connection has been identified using this query executed within weblogs:
#type=accesslog
| regex("(?<webclient>[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+)")
| statuscode>=400
| regex("\" (?<statuscode>[0-9]{3}) ")
| join({ sshd
| regex("(?<ipaddress>[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+)")
| invalid}, field=webclient, key=ipaddress, repo=accesslogs)The first three lines of the query do the following:
Extract the HTTP statuscode into a field
Match events that have a type of
accesslogand a statuscode above 400 (an error condition).Extract the IP address of the request into a field webclient
The join() function then finds entries in the
accesslogs repository, first by extracting the IP address
of the entry, and then filtering the search where the event contains
sshd and invalid. The resulting list of events
will contain a list of failed SSH login attempts.
Mar 10 07:49:00 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:07 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:36 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:36 humiobase sshd[1850622]: Connection closed by invalid user user1 192.168.1.18 port 49361 [preauth]
Then the join() matches events in the two
repositories. The field
parameter specifies the field from the weblogs repository
(the 'table' on the left) that should be matched to the corresponding
events in the accesslogs repository on the right. As an
inner join, this means we will filter the events in weblogs
for only the IP addresses where an SSH connection in
accesslogs exist. In essence, we are comparing the
ipaddress on the subquery with the field
webclient within the main query.
The result is that the join query simplifies the list of events to those highlighted below; the other events are ignored.
Mar 10 07:49:00 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:07 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:36 humiobase sshd[1850622]: Failed password for invalid user user1 from 192.168.1.18 port 49361 ssh2
Mar 10 07:49:36 humiobase sshd[1850622]: Connection closed by invalid user user1 192.168.1.18 port 49361 [preauth]
Mar 10 07:51:16 humiobase sshd[1854832]: Accepted password for mc from 192.168.3.33 port 60928 ssh2
Mar 10 07:51:16 humiobase sshd[1854832]: pam_unix(sshd:session): session opened for user mc(uid=1000) by (uid=0)And then further filters the list of weblogs event list by matching the IP address as shown in the highlighted items, with the non-highlighted items ignored:
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/automated-alerts-manage.html HTTP/1.1" 200 249251
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/humio-cloud-identity-providers-saml.html HTTP/1.1" 200 244289
192.168.3.33 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/humio-cloud-identity-providers-configuration.html HTTP/1.1" 200 243435
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-scatter.html HTTP/1.1" 404 260601
192.168.1.49 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-sankey.html HTTP/1.1" 200 252146
192.168.1.76 - - [10/Mar/2023:11:16:32 +0000] "GET /ingesting-data/log-formats/kubernetes HTTP/1.1" 404 369Resulting in a final list of events matching:
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-scatter.html HTTP/1.1" 404 260601
Notice that the event from IP address 192.168.1.76 even
though it's an error access code, is not included, because the IP
address hasn't been located in the ssh logs.
Left Joins
The left join returns everything in the primary and anything that matches from the subquery, i.e. the original events and the intersection of them. From the diagram, we return everything in the left table of events, and all the events that match both tables.
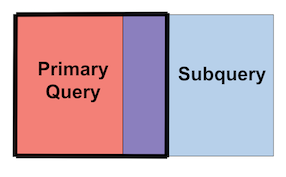 |
Figure 190. Left Joins
As an example of a left join, we can use the same data as before, this time returning all the information about IP addresses accessing using multiple methods. For this we can use this query, this time executed within the accesslogs repository:
#type=accesslog
| regex("\" (?<statuscode>[0-9]{3})")
| statuscode>=400
| regex("(?<ipaddress>[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+)")
| join({username=*
| regex("(?<webclient>[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+)")}, field=webclient, key=ipaddress, repo=accesslogs, mode=left)
As before, we extract the statuscode, pick all the entries that have an
error statuscode (higher than 400), and extract the IP address. The
join() then matches the IP address with any entries
in the accesslogs repo, this time looking for entries where
we have a username. The result will be a list of all the events with an
error status and those that include an IP address with a username from
the access logs.
The input data is the same, but just using the web access log:
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/automated-alerts-manage.html HTTP/1.1" 200 249251
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/humio-cloud-identity-providers-saml.html HTTP/1.1" 200 244289
192.168.3.33 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/humio-cloud-identity-providers-configuration.html HTTP/1.1" 200 243435
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-scatter.html HTTP/1.1" 404 260601
192.168.1.49 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-sankey.html HTTP/1.1" 200 252146
192.168.1.76 - - [10/Mar/2023:11:16:32 +0000] "GET /ingesting-data/log-formats/kubernetes HTTP/1.1" 404 369The resulting list of events is:
192.168.1.18 - - [09/Mar/2023:17:24:42 +0000] "GET /falcon-logscale/dashboards-allwidgets-scatter.html HTTP/1.1" 404 260601
192.168.1.76 - - [10/Mar/2023:11:16:32 +0000] "GET /ingesting-data/log-formats/kubernetes HTTP/1.1" 404 369Join Syntax
The join() function's signature looks like this
join({subquery}, field=arg1, key=arg2, repo=arg3, mode=inner
| left)
The unnamed subquery argument, and the named field
and key arguments, are required. The named
repo,
include, and
mode parameters are optional.
There are other options available. Please see the
join() reference page for more details.
First, let's consider a join query against a single repository. In that
scenario, there is no need to define the optional
repo argument. The query will
look like this
primary query
| join({subquery}, field=arg1, key=arg2)
So to break down how the join() function is used
The primary query is any valid LogScale query. This provides the first set of results you wish to work with.
The arguments you pass to the
join()function define what results should be combined and how.The subquery is any valid LogScale query. This provides the second set of results you wish to combine with those from your primary query.
The field parameter's value (
arg1) defines the field name in the primary query. This value will be used to match data in the subquery.The key parameter's value (
arg2) defines the field name in the subquery. This value will be used to match data in the primary query.
If the field names being used in field and key are identical, you can use the simplified syntax
primary query
| field =~ join({subquery})In the above example, the field argument would be the actual field name. For example, if both queries share a field named host that you wish to join on, you would use:
primary query
| host =~ join({subquery})Joining Two Repositories
In addition to joining two queries against a single repository, the
join() function can also be used to return a result
set from more than two repositories. To do so, use the optional
repo parameter to define the
repository (as arg3) you want the subquery to run
against.
primary query
| join({subquery}, field=arg1, key=arg2, repo=arg3)Note
The user running the join() query must have
permissions on both repositories.
Limitations of Live Joins
Joins are implemented by starting two queries: the main query and the subquery. For static queries, the subquery runs first and then the main query runs.
Joins can simulate being live, by repeatedly running at a time interval determined by the server. This means that results will appear when the query is re-run, not when data is ingested, unlike for other kinds of live queries.
LogScale notions of liveness and joins are not compatible, meaning that
the results of live queries using the join()
function may become incorrect over time. Instead of running these
queries fully live, they are internally repeated at an interval
determined by the server, which can lead to a delay on new results that
depend on the resources the query uses.
Important
You should avoid using the join() function in
Alerts because, being a heavy query
typically not suited for alerts, it will produce unexpected results.
Since the join is repeated when the server schedules it, there is no
guarantee the alert gets data for the correct interval, leading to
incorrect alarms. Instead, try using
Scheduled Searches.
Support for using join() functions in alerts may
be removed in future versions.
Best Practices for Join Queries
LogScale recommends the following when running
join() queries.
For best performance, the query for the right of the join should be significantly smaller than the query on the left. Joins are expensive operations resource wise, as two queries need to be executed and then matched against each other. With a smaller right-hand query, the number of lookups and matches against the query on the left will be reduced resulting in better performance.
If your
join()query key is constantly changing with live data, you should be aware that using live queries with thejoin()function has some significant limitations, the reasons are explained at Limitations of Live Joins and atjoin().When debugging an inner join query, temporarily set the join mode to left (
join(mode=left)). This will help you debug your query by showing all results matched or unmatched by the join clause.First write the subquery alone to make sure the results are what you expect. Once they are, then you can confidently include it in a join.