
Stage 3: Promote Secondary to Active
In the third phase of failover, you promote the secondary cluster to active. The architecture is shown in the following diagram:
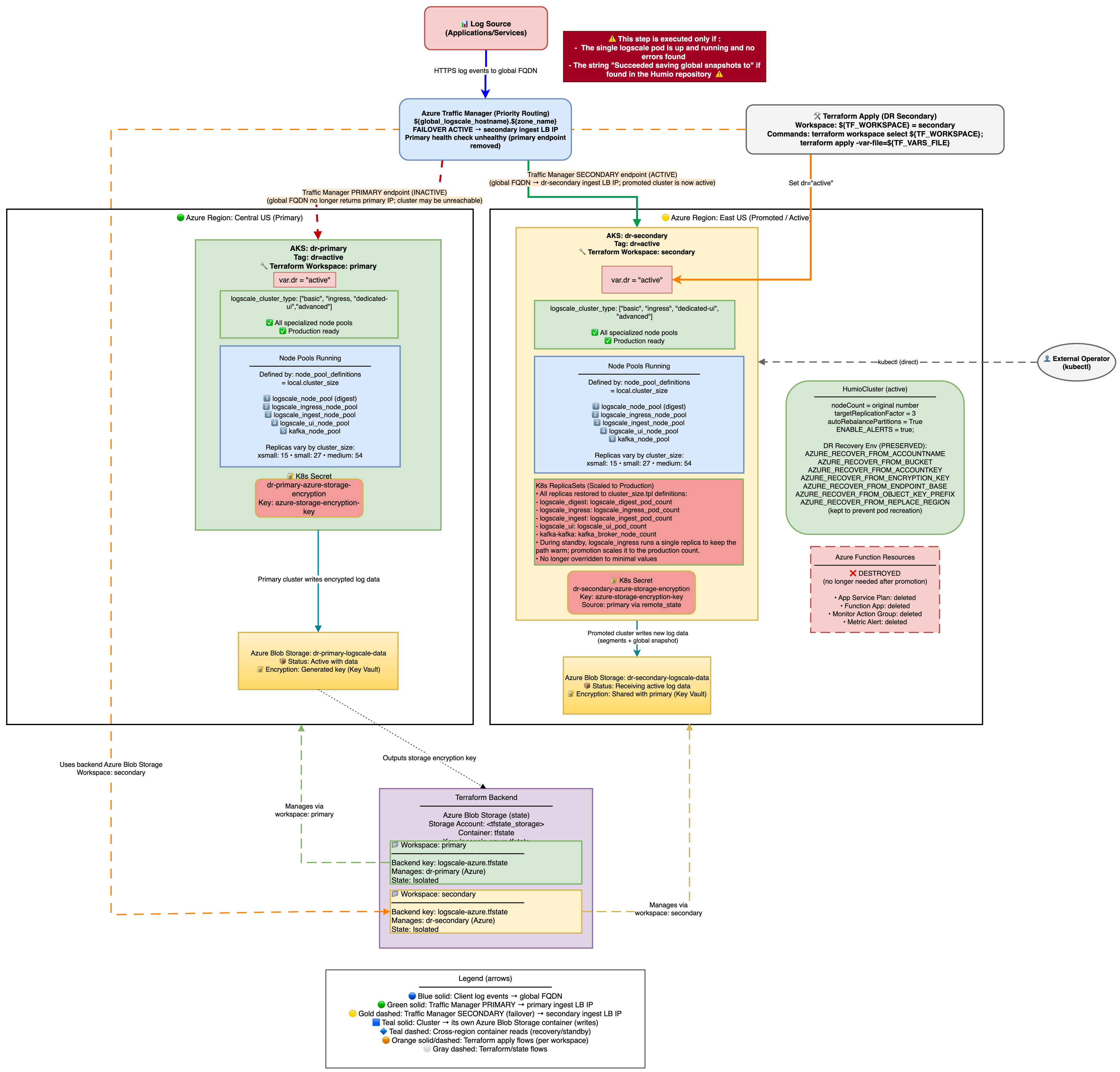 |
Once the LogScale pod is running and has successfully read the global snapshot from the primary Azure Blob container, the cluster can be promoted to active status.
Zero-Downtime Promotion (Two-Phase Apply)
This guide previously described a two-phase, zero-downtime promotion using
dr_use_dedicated_routing=false while switching to
dr="active".
Current implementation status: This two-phase, zero-downtime promotion is not supported by the Terraform in this repo:
validation.tfallowsdr_use_dedicated_routing=falseonly whendr="standby".main.tfforcesdr_use_dedicated_routing=truewhendr != "standby".
What is supported:
Use
dr_use_dedicated_routing=falsewhile the cluster is stilldr="standby"so the single digest pod can serve UI/ingest during failover.Promote using the single-apply procedure in the next section and expect a short window of 503s until UI/Ingest pods are Ready.
Standard Promotion (Single Apply)
If downtime during promotion is acceptable, you can use a single apply:
Actions:
# Edit tfvars, switch to active
vi secondary-<region>.tfvars
dr = "active" # or dr = "" for non-DR mode (both work for promotion)
# dr_use_dedicated_routing defaults to true (pool-specific routing)
# Apply in secondary state
terraform init -backend-config=backend-configs/production-secondary.hcl -reconfigure
terraform apply -var-file=secondary-<region>.tfvarsWhat changes automatically:
Creates UI and Ingest node pools (if
logscale_cluster_typerequires them) - these are not present in standby mode.Scales node groups to production sizes.
Sets production replication factor and enables auto-rebalance.
Enables alerts by setting
ENABLE_ALERTS=true.Humio operator scales to 1 and HumioCluster
nodeCountfollows production values.Azure Function resources are destroyed (no longer needed on active cluster).
Traffic Manager endpoint is preserved - The secondary endpoint remains registered in Traffic Manager to ensure traffic continues routing to the promoted cluster.
Traffic Manager Endpoint Persistence
Important
Important: The secondary cluster's Traffic Manager endpoint is managed
based on manage_global_dns, not dr
status. This ensures the endpoint persists during DR promotion.
The endpoint registration logic in main.tf:
count = !var.manage_global_dns && local.traffic_manager_profile_id != "" ? 1 : 0This design ensures:
The secondary endpoint is created for any cluster that doesn't manage global DNS (that is, not the primary)
The endpoint remains when promoting from
dr="standby"todr="active"Traffic Manager continues routing to the secondary cluster after promotion
The endpoint is only removed if the secondary cluster is destroyed
No hardcoded state file names - works with any naming convention
Why manage_global_dns instead of dr
status:
The primary cluster sets manage_global_dns = true and creates
the Traffic Manager profile with its own endpoint. The secondary cluster
sets manage_global_dns = false and registers itself as a
secondary endpoint on the primary's Traffic Manager profile.
This approach decouples the endpoint lifecycle from the DR state:
Primary (
manage_global_dns = true): Creates Traffic Manager profile and primary endpointSecondary (
manage_global_dns = false): Registers as secondary endpoint, persists throughdrstate changes
Verification after promotion:
# Verify Traffic Manager endpoints
az network traffic-manager endpoint list \
--profile-name <profile-name> \
--resource-group <primary-rg> \
-o table
# Expected: Primary shows "Degraded", Secondary shows "Online"AZURE_RECOVER_FROM_* Environment Variable Preservation
Current behavior: The AZURE_RECOVER_FROM_* environment
variables are set only when dr="standby" and are removed when
promoting to dr="active" (or dr=""). This
follows the Terraform locals logic
(local.dr_recovery_envvars is conditional on
var.dr == "standby").
Operational implication: Removing these env vars changes the HumioCluster spec and may cause the operator to roll/recreate pods during promotion. Plan for a restart window as part of the promotion process.
Verify promotion:
kubectl get humiocluster -n logging --context aks-secondary -o jsonpath='{.spec.environmentVariables}' | jq '.[] | select(.name | startswith("AZURE_RECOVER"))'
kubectl get humiocluster -n logging --context aks-secondary -o jsonpath='{.spec.nodeCount}'
# => production value
kubectl get pods -n logging --context aks-secondary
# => all pods runningPreventing Automatic Failback (Traffic Manager Priority)
Traffic Manager uses Priority routing. In this implementation:
The primary endpoint (created by the primary state) is priority 1
The secondary endpoint (created by the secondary state) is priority 2
After you promote the secondary cluster, if the primary endpoint becomes healthy again, Traffic Manager will automatically route traffic back to the primary (priority 1). If you need to stay on the promoted secondary until a planned failback, disable the primary endpoint (manual change) or adjust endpoint priorities.
Warning
A later terraform apply in the primary state will re-assert the primary endpoint configuration (enabled/priority). Treat this as an explicit operational decision.