
Split an event structure that includes an array into multiple distinct events with each array element.
Omitted Argument NamesThe argument name for
fieldcan be omitted; the following forms of this function are equivalent:logscalesplit("_events")and:
logscalesplit(field="_events")
When LogScale ingests data into arrays, each array entry is turned into
separate attributes named [0],
[1], ...
This function takes such an event and splits it into multiple events based
on the prefix of such [N] attributes, allowing for aggregate functions
across array values.
When the function is called, each split event generated is given a unique index ID in the _index field. This can be used to identify the individual event.
Note
The split() function is not very efficient, so it
should only be used after some aggressive filtering.
split() Examples
In GitHub events, a PushEvent contains an array of commits, and each
commit gets expanded into subattributes of
payload.commit_0,
payload.commit_1, ....
LogScale cannot sum/count, etc. across such attributes.
split() expands each
PushEvent into one
PushEvent for each commit so they can be
counted.
type=PushEvent
| split(payload.commits)
| groupby(payload.commits.author.email)
| sort()There might be a case where your parser is receiving JSON events in a JSON array, as in:
[
{"exampleField": "value"},
{"exampleField": "value2"}
]In this case, your @rawstring text contains this full array, but each record in the array is actually an event in itself, and you would like to split them out.
First you need to call parseJson(), but when
@rawstring contains an array, the
parseJson() function doesn't assign names to the
fields automatically, it only assigns indexes. In other words, calling
parseJson() adds fields named something like
[0].exampleField,
[1].exampleField, etc. to the current
event.
 |
Since split() needs a field name to operate on
before it reads indexes, it seems like we can't pass it anything here.
But we can tell split() to look for the empty field
name by calling split(field="").
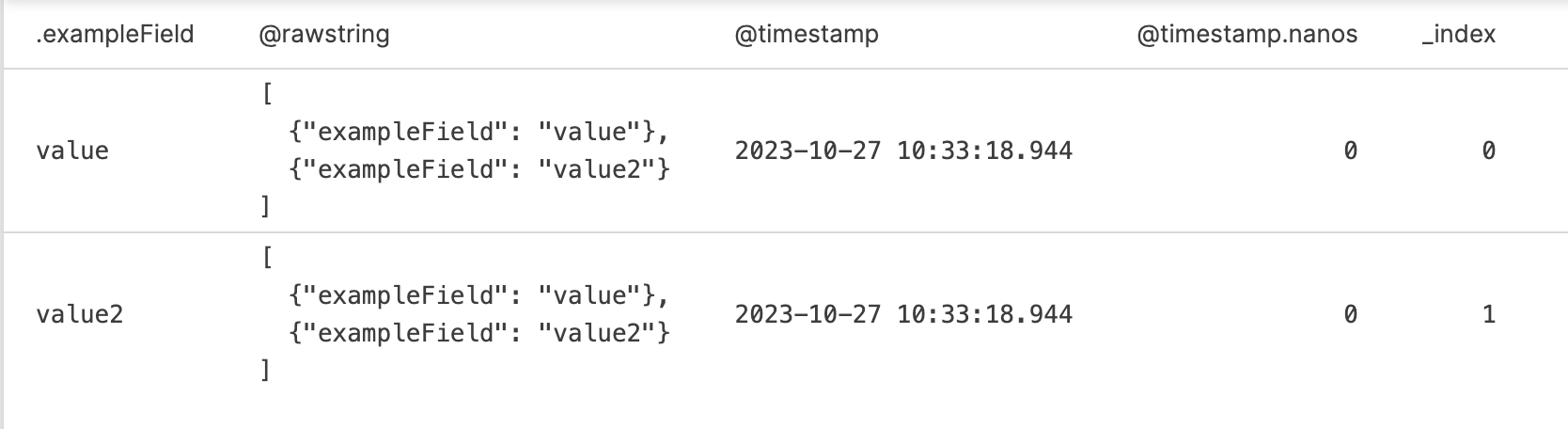
This means that parsing the above with:
parseJson()
| split(field="")
will produce two events, each with a field named
exampleField, and with an additional field,
_index containing the index (count) of the original
data so that each individual split() event can be
identified:
 |
Alternatively, we can tell parseJson() to add a
prefix to all the fields, which can then use as the field name to split
on:
parseJson(prefix="example")
| split(field="example")
Unfortunately this adds the example
prefix to all fields on the new event we've split out, so you may prefer
splitting on the empty field name to avoid that.