
Network Architecture
The GCP DR infrastructure uses a regional VPC topology with firewalls, node pools, and label selectors to route traffic during normal operations and during failover.
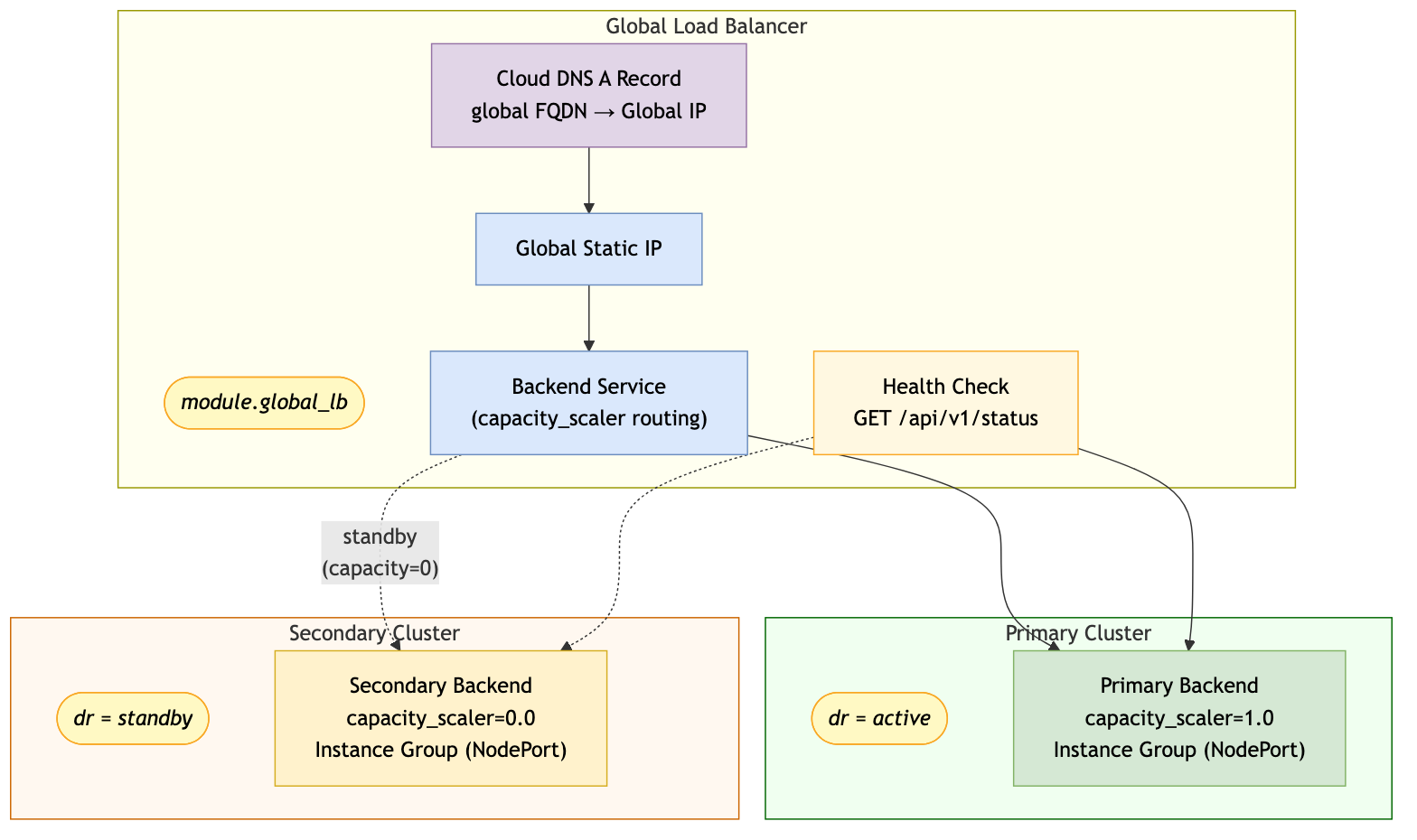
GLB Architecture Overview:
 |
Subnet / VPC Configuration
Each GCP region has a dedicated VPC with the following structure:
| Component | Configuration | Purpose |
|---|---|---|
| VPC Network | Regional, managed by Terraform | Isolates primary and secondary clusters |
| Subnets |
Configurable CIDR range per region
(gcp_cidr_range)
| Separate IP ranges per region |
| Cloud NAT | Per region, configured on Cloud Router | Outbound internet access from private nodes |
| Cloud DNS |
Global zone (if manage_global_dns=true)
| Global DNS records managed by primary only |
Firewall Rules
| Rule | Direction | Source | Destination | Protocol/Port | Purpose |
|---|---|---|---|---|---|
| Allow Internal | Ingress |
var.gcp_cidr_range (default 10.128.0.0/20)
| All | TCP/UDP 80-65535 | Intra-cluster communication |
| Allow GLB Health Checks | Ingress | 130.211.0.0/22, 35.191.0.0/16 | All | TCP 31036, 10256, 8080 | GCP health check probes (NodePort, kubelet, readiness) |
| Allow Subnet Proxy | Ingress |
var.gcp_subnetwork_proxy_cidr_range
| All | TCP 443, ICMP | Internal ingest LB (advanced cluster type only) |
| Allow Egress | Egress | All | 0.0.0.0/0 | All | Outbound internet via Cloud NAT |
Node Pool Topology by DR Mode
Node pools are deployed based on logscale_cluster_type
and provision_kafka_servers, not by
var.dr mode. The standby cluster uses the same node
pool configuration as active — the cost savings come from the
humio-operator being scaled to 0 replicas (no LogScale pods running).
| Node Pool | Deployment Condition | Purpose |
|---|---|---|
| Digest | Always deployed (no count condition) | Core LogScale processing (queries, segment management) |
| Kafka |
var.provision_kafka_servers == true
| Strimzi Kafka brokers for partition management |
| Ingest |
logscale_cluster_type == "advanced"
| Data ingestion and parsing workloads |
| UI |
logscale_cluster_type in ["dedicated-ui",
"advanced"]
| User interface and API endpoints |
Note
GCP does not have an Ingress node pool. GCP uses native GKE Load
Balancer via NodePort service (deploy_nginx_ingress =
false), unlike AWS/Azure which use nginx ingress controllers.
Additional cluster-level settings by DR mode:
| Component | Active (dr="active") | Standby (dr="standby") |
|---|---|---|
| Humio operator | 1 replica | 0 replicas |
| HumioCluster nodeCount | cluster_size value | 1 (declared, not running) |
| HumioCluster nodePools | Full nodePool spec | null (prevents reconciliation loop) |
| Replication factor | Production value | 1 (overridden) |
| Auto rebalance | Enabled | Disabled |
Why Standby Has Minimal Running Workloads
The standby cluster is designed for minimal cost with rapid failover capability:
No active LogScale workloads: During standby, the humio-operator is scaled to 0 replicas, so no LogScale pods run. Node pools are provisioned but idle.
Recovery via snapshot: Failover recovery reads the global snapshot from the primary GCS bucket using a single digest pod. Ingest workloads only resume after promotion.
On-demand scaling: When promoted to
dr="active", the Cloud Function scales the operator to 1 replica, which then reconciles the HumioCluster CR.Resource efficiency: No idle LogScale pods consuming compute resources — standby cost is minimized to Kafka brokers and infrastructure components.
What Runs on Standby
Kafka brokers: 3-5 replicas running. Required for LogScale partition management; keeping them running avoids 10-15 minutes of Kafka startup delay during failover.
NodePort service: Exposes port 8080 for GLB health checks. Uses DR-aware label selectors (
app.kubernetes.io/name=humio,humio.com/feature=OperatorInternal) to target query-capable pods.cert-manager: Running to maintain valid TLS certificates.
TopoLVM: Running for LVM volume provisioning.
Digest node pool: GKE nodes provisioned but no LogScale pods running until operator scales up.
Why nodePools = null on Standby
When dr="standby", the HumioCluster spec sets nodePools
= null to prevent the humio-operator from entering a reconciliation
loop. The shared logscale-kubernetes module generates
nodePool specs for all pool types (digest, UI, ingest)
with nodeCount=0 for pools not deployed on standby. The
operator interprets these zero-count pools as stale status entries,
cleaning them up each cycle and preventing the digest pod from being
created.
Important: nodePools is tied to var.dr == "standby", NOT to
dr_use_dedicated_routing. During two-phase promotion:
Phase 1 (
dr="active",dr_use_dedicated_routing=false): nodePools are restored so UI/Ingest pods begin scaling upPhase 2 (
dr_use_dedicated_routing=true): Pool-specific selectors are enabled once pods are ready
Nulling nodePools during Phase 1 would cause a 503 outage in Phase 2 because selectors would update instantly but pods would take minutes to start.
Request Flow (Internet to LogScale)
DNS Resolution: Client resolves
<global-hostname>.<zone-name>to the global GLB IPGlobal Load Balancer: Routes to backend based on
capacity_scalerand health checks:Primary backend:
capacity_scaler=1.0(receives all traffic)Secondary backend:
capacity_scaler=0.0(receives no traffic until failover)
GKE NodePort Service: GLB connects to GKE NodePort service (port 8080 -> 31036) on the digest node pool instance group
Label Selector Routing: NodePort service uses DR-aware selectors to route to appropriate pods:
Active:
app.kubernetes.io/name=humio + humio.com/feature=OperatorInternal(or pool-specific selectors whendr_use_dedicated_routing=true)Standby: Same selectors, but no pods match until operator scales up
LogScale Pod: Handles request (queries, log ingestion, etc.)